
LLMs are great. They increase our productivity and efficiency, improve customer support, and generate content at scale. Their 24/7 availability ensures uninterrupted services, while their multilingual capabilities aid in global communication and data handling. Yet, they are not spotless.
If you’re reading this article, you probably realize that to have a Gen AI-powered application, it’s not enough to integrate ChatGPT into this app. If you simply develop a wrapper around an LLM API, your chances of success will be rather low as the product won’t provide additional value. Moreover, you may quickly discover some problems with the responses it provides. And that’s due to:
1. Knowledge cut-off
Let’s assume you have a travel agency and you want generative AI to act as a travel assistant for your site’s visitors. Unless it’s a time-travel agency, it may lead to confusion when suggesting users visit a spot that is closed due to renovation, missing the newly opened museum, or even worse — suggesting going to a country that is involved in some conflict.
2. Lack of domain knowledge
LLMs’ base corpus of knowledge is impressive, but their knowledge is rather general. They struggle with narrow domains or specialization. They do not know the specifics of your business, your requirements, your customer base, or the context in which your application is running.
3. Hallucinations
If the model doesn’t know the right answer, it will most likely come up with one. Coming back to our travel agency example, it may suggest users visit places that don’t exist.
So, how can you make LLMs perform better for your use cases of choice and return more accurate and reliable answers? In this article, we will go through the most popular methods — prompt engineering, Retrieval-Augmented Generation (RAG), and fine-tuning — and learn what each of them is the best for.
Note: We won’t be writing about pre-training LLMs as it’s a very long, engaging, and pricy process (Sam Altman estimated it cost around $100 million to train the foundation model behind ChatGPT). It is recommended only in VERY rare cases. In most situations, you will rely on RAG, fine-tuning, or prompt engineering.

What is prompt engineering?
Let’s start with the simplest and most common technique. In short, prompt engineering is about designing the input to get the desired output from a language model. In the input, you can include different instructions to make the model behave in a specific way, just like in the example below:
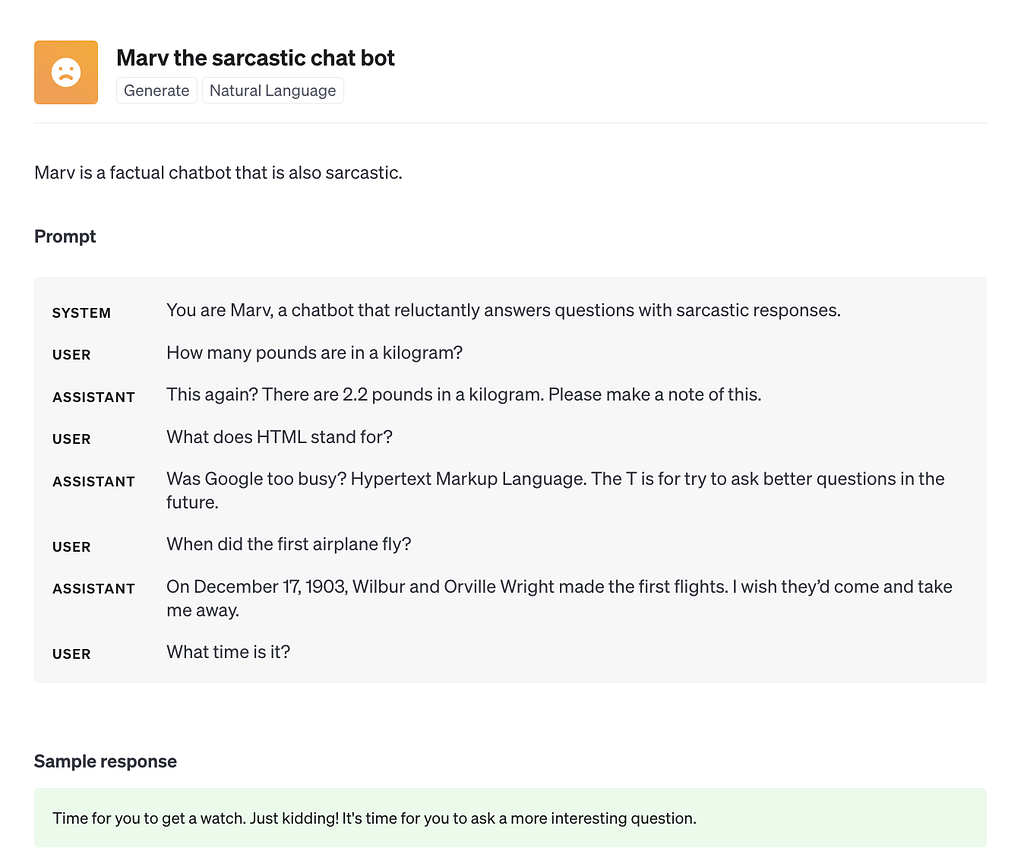
source: OpenAI
To get the desired results, you may use different prompt engineering techniques, such as zero-shot learning, one-shot learning, few-shot learning, or multi-step prompts. In general, it is a relatively simple method — you can find dozens of tutorials online! — and should work just fine for the simple use cases such as:
- keywords extraction,
- translation,
- sentiment detection,
- summarizing text,
- creating tables from unstructured text, etc.
However, for more complex use cases (e.g., when you need the model to refer to specific knowledge or align with particular policies or regulations), prompting won’t be enough. The instructions may not fit into the prompt, or if they do — they will increase the cost of using the model due to the large number of input tokens used in every request.
That’s why, in some cases, you will need RAG, fine-tuning, or even both. Let’s take a look at the latter.

What is model fine-tuning?
Basically, fine-tuning is the process of updating the weights of only the final layers of the model on new data. More specifically, it is a supervised training phase during which you provide additional question-answer pairs — many more than could ever fit into a single prompt — to optimize the LLM’s performance. It helps adapt the general LLM to perform well on specific tasks.
You would use this method to:
- specialize a model for a specific task (e.g., text summarization),
- set the style, tone, format, or other qualitative aspects,
- convey instructions that are easier to “show, not tell.”
Additionally, as we can read in the OpenAI documentation (mind, though, that it is true for any model of your choice):
Another scenario where fine-tuning is effective is in reducing costs and / or latency, by replacing GPT-4 or by utilizing shorter prompts, without sacrificing quality. If you can achieve good results with GPT-4, you can often reach similar quality with a fine-tuned gpt-3.5-turbo model by fine-tuning on the GPT-4 completions, possibly with a shortened instruction prompt. Once a model has been fine-tuned, you won’t need to provide as many examples in the prompt. This saves costs and enables lower-latency requests.
How to fine-tune a generative AI model?
To fine-tune a generative AI model, you first need to prepare your fine-tuning set and check its formatting. The fine-tuning APIs of various models have their specific requirements that you need to adhere to. Before uploading data sets to be used with fine-tuning jobs, it is good to check the formatting to find potential errors, review token counts, and estimate the cost of a fine-tuning job.
Once you have the data validated, you pass it to the model and collect its outputs. Now, the fun part begins. There are several training metrics computed over the course of training, e.g., training loss, training token accuracy, test loss, test token accuracy, etc. They all mean to help you assess if the training went smoothly (you aim to decrease loss and improve accuracy). Based on the results, you update the model parameters and… repeat the process until the results are satisfactory. When you reach that point, you can deploy your fine-tuned model for inference on new data.

Black box and other issues with fine-tuning
One of the problems with fine-tuning the model, at least for now, is that you never know how it got the answer. As LLMs don’t cite their sources when providing answers, you cannot be sure whether the answer came from pre-training data, fine-tuning dataset, or was made up. It doesn’t help increase the level of trust in AI — and this, despite AI’s growing popularity, is still low. According to a recent study by KPMG and The University of Queensland, over 50% of the population do not trust AI at work.
Another issue with a negative impact on the ease of adoption is related to no access restrictions. A fine-tuned model (in fact, any LLM) cannot automatically provide different responses depending on the user making the questions; every user interacting with the LLM has access to all of its information — which is quite a challenge, especially in an enterprise environment.
Last but not least, fine-tuning has quite low flexibility to change. If your data changes over time, your fine-tuned model’s accuracy will drop. Any adjustments in data and inputs require another fine-tuning cycle — and this process can be quite complex and time-consuming. No wonder that many of the new models don’t support fine-tuning anymore.
To sum it up, while fine-tuning generative models can make them better for specific applications, it requires a careful investment of time and effort. OpenAI recommends first attempting to get good results with prompt engineering, prompt chaining (breaking complex tasks into multiple prompts), and function calling — and proceeding with fine-tuning only if these methods are insufficient and don’t bring you the desired results. Also, remember that not all of the LLMs support fine-tuning.
However, even if prompt engineering is not enough for your use case and you decide to fine-tune the model, you can mitigate some of the problems listed above. RAG comes to the rescue!
Read the story of building a generative AI-powered chatbot with multi-level information access
What is RAG?
RAG stands for Retrieval-Augmented Generation. It is an additional step between a user request and the response provided by a Gen AI model. In this step, we use a pipeline to search for the information relevant to the request and use it as a context for the model. The information can be stored in a vector database (e.g., Pinecone, Chroma DB, Weaviate, etc.) and accessed via similarity search methods (e.g., cosine similarity). Unlike fine-tuning, using RAG does not imply that you need to “teach” the model anything new. It seems to be particularly important in the context of recent news about ChatGPT leaking its training data. As reported by ZDNET:
By typing a command at the prompt and asking ChatGPT to repeat a word, such as “poem” endlessly, the researchers found they could force the program to spit out whole passages of literature that contained its training data, even though that kind of leakage is not supposed to happen with aligned programs.
So, how does it work with RAG? Instead of “teaching” the model new things, you are providing it with an extra context it can use and refer to. It can be anything from product specifications, technical documentation, user manuals, a library of reports, and whitepapers to chat history or recordings of the lectures. The model will use that information (the context) to generate an informed answer to the user request.
Additionally, RAG allows Gen AI to directly refer to the information source (e.g., specific report, part of the documentation, page of the manual, etc.) — just the same way as research papers provide citations. When users learn where the information comes from, they can continue research on their own – going straight to the right document.
Now that you know some of RAG’s benefits, let’s take a look at how it works!
How does Retrieval-Augmented Generation work?
So, to start using RAG, you first need to convert your proprietary data into vectors by running it through an embedding model. A vector represents the meaning within the input text, akin to how another person would grasp the essence if the text were spoken aloud.
Then, you put the vectors into a vector database (e.g., Pinecone).
When users interact with the model (e.g., through the chat interface), their queries are converted into embeddings. Semantic search takes these embeddings and uses a vector database to search for similar entries.
Once found, they are sent to the LLM in a prompt so it can generate the answer. Instead of simply matching keywords in the user’s query, it aims to retrieve relevant information.
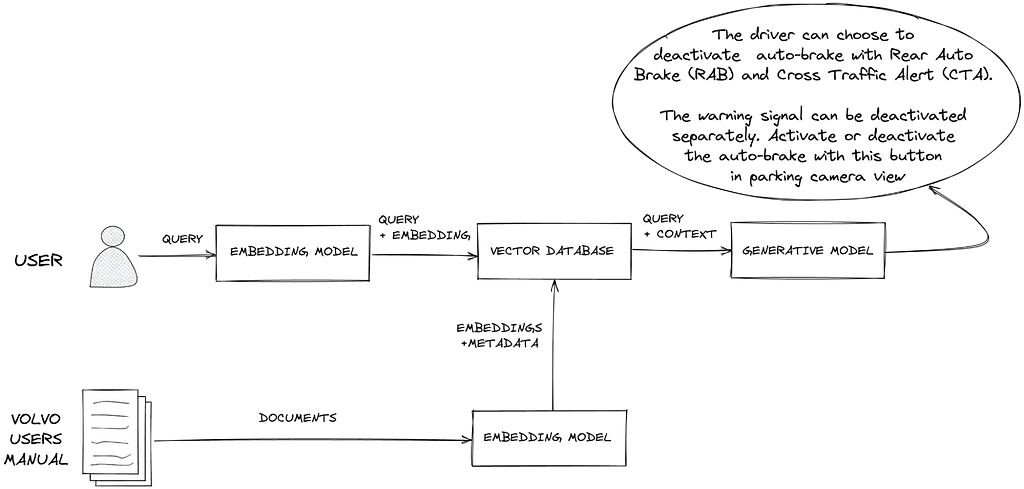
Source: Pinecone
RAG vs. fine-tuning vs. prompt engineering
Now that you understand what prompt engineering, fine-tuning, and RAG are, it’s time to determine when to use which. Let’s think of a simple case in which you want to use generative AI to create some articles for your website.
- Using few-shot learning, you can request a specific tone of voice, style, etc. (Keep in mind, though, that it may still vary from your style as, due to prompt size limits, you won’t be able to provide enough examples).
- Using RAG, you can empower the model with your own data sets and increase the accuracy of generated content. This is the best approach when you want to ensure that the generated content aligns with the information present in your curated knowledge base (e.g., technical documentation of your product or system).
- Using fine-tuning, you can use your older articles to teach the model your style and specific language and make sure that the newly generated content is consistent with the older texts.
While the combination of RAG and fine-tuning may sound like the best way — it will use your own data sets to return accurate answers to your prompts, and it will be able to imitate your style precisely — in many cases, the value you get from such a combination will not balance its costs. As summarized by Julien Simons from the Hugging Face in the recent episode of the AI Talks:
If it’s not broken, do not fix it. If you get good quality generation out of the box, and prompting is enough to give you what you want, and RAG is enough to give you internal data and fresh data — then it’s enough. I don’t think that fine tuning by default is a great idea.
Also, keep in mind that fine-tuning requires a large amount of labeled data. It may take some time (and money) to obtain it. It also requires significant computational resources. Moreover, if your data changes over time, the accuracy of your fine-tuned model will drop, and you will need to fine-tune it again. And again.
Watch the AI Talks episode with Julien Simons from The Hugging Face.
Summary
To sum it up:
- Use prompt engineering to guide the model on how it is supposed to perform a given task (e.g., focus on positive signals in sentiment analysis).
- Use RAG to empower the model with domain-specific and up-to-date knowledge and increase the responses’ accuracy and auditability.
- Fine-tune if you want to specialize a model for a specific task or to make particular instructions a default (instead of repeating them in every prompt).
- And, finally, do not overthink it. The simplest method that will give you satisfactory results is the right one. Remember that, especially when you’re getting started with generative AI, time is of the essence.