


Even though it was OpenAI that brought public attention to generative AI, it is not a monopolist in this field. Its open-source alternatives can offer similar performance and a higher level of transparency and often require less computational power. They attract users who are concerned about their data privacy and who want more control over the data training process. The question is: can they really compete with the OpenAI models?
There is no doubt that Gen AI is THE tech trend of 2023. It attracts the most publicity, the most investment, and the most funding. Yet, the adoption of Gen AI doesn’t come without fears, uncertainties, and doubts.
On the one hand, it offers significant benefits, including increased efficiency and cost savings. There are dozens of inspiring GPT use cases serving as living proof of the feasibility of such projects. On the other hand, we regularly hear news about data leaks, lawsuits against different artificial intelligence companies, and various institutions banning ChatGPT and other tools due to data security concerns.
Is open-source a remedy to these challenges and fears? In this article, we will take a look at the available alternatives to ChatGPT and its base models.
Table of Contents
In open source we trust
A recent Digital Ocean report shows that over 30% of startups and SMBs and 28% of corporations choose public domain solutions for half of their software. Moreover, 80% of the surveyed enterprises expect to increase these values for emerging technologies. For those who already chose open-source, it is a key part of their security strategy.

One of the main reasons behind the growing popularity of open solutions is trust. According to last year’s Enterprise Open Source Report, 89% of IT leaders see enterprise open-source as more secure or as secure as proprietary software. It is valued mainly for well-documented security patches that are regularly released and mature communities that are reviewing and testing the code on a regular basis. When we narrow it down to the field of public domain Gen AI models, the focus shifts to data protection (companies don’t want their data to be used for training large models) and intellectual property rights.
The second reason, declared by 79% of those who use open solutions in their companies, is that they provide flexibility to customize solutions to meet specific needs and company standards. In the case of generative AI development, it is particularly important to oversee the training process and understand the potential biases.
Best open-source alternatives to GPT models
Now that we know why it’s worth exploring open-source AI models, let’s take a look at the most popular ones.

LLaMA
Born and grown in FAIR, Meta’s AI research lab, LLaMA is one of the most important language models. It is a family of LLMs that come in four different sizes: 7, 13, 33, and 65 billion parameters. It may not sound impressive compared to the 100 trillion parameters of GPT-4. Or even to GPT-3’s 175 billion parameters. But don’t underestimate it! Despite the fewer parameters, LLaMA models were trained on a higher number of tokens. The idea behind it is that smaller models pre-trained on more tokens are easier to retrain and fine-tune for specific use cases. As a result, LLaMA-13B outperforms GPT-3 on the common sense reasoning tasks.
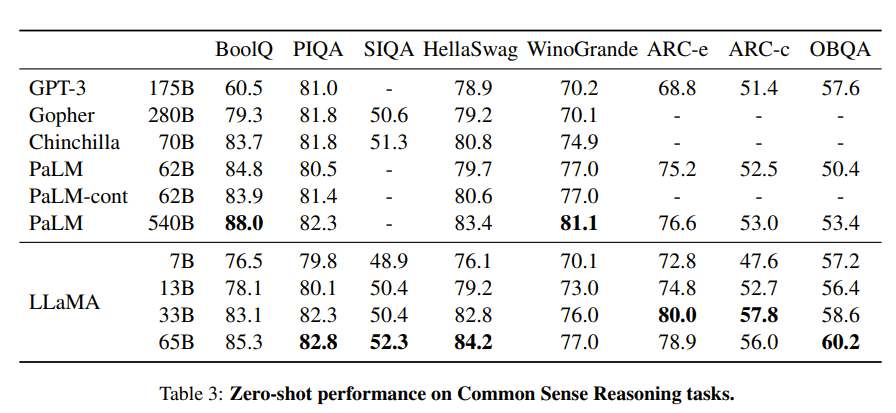
Unfortunately, the model was released under a noncommercial license focused on research use cases. The intention, as explained by Meta, is “further democratizing access to artificial intelligence (AI)” to spur research into its problems. The access to LLaMA is therefore limited to academic researchers, government-affiliated organizations, civil society, and research labs on a case-by-case basis.
Used in: Vicuna, GPT4ALL, Alpaca
UPDATE [21.07.23]: Great news for everyone hoping for Llama to become available for commercial use! On July 18, Meta announced the launch of the model’s next generation – Llama 2. Developed in cooperation with Microsoft, the new version is free for both research and commercial use. The downloadable release package includes model weights and starting code for pre-trained and fine-tuned models in three sizes: 7, 13, and 70 billion parameters.
Llama 2 was trained on a dataset of 2 trillion tokens (meaning 40% more than its predecessor) and fine-tuned on over 1 million human annotations. Its context length is 4096, which is twice that of Llama 1.
Read also: Is Llama 2 Better Than GPTs?
OPT
Open Pretrained Transformer language model (OPT) was released by Meta in May 2022. It contains 175B parameters (same as GPT-3) and was trained on multiple public datasets, including The Pile and BookCorpus.
Unfortunately OPT is currently available only for research purposes under a non-commercial license.
By sharing OPT-175B, we aim to help advance research in responsible large language model development and exemplify the values of transparency and openness in the field.
Meta, “Democratizing access to LLMs with OPT-175B”

MPT-7B
MPT-7B is a part of MosaicPretrainedTransformer (MPT) models developed by MosaicML. It was trained on 1T tokens of English text and code; it is said to be optimized for efficient training and inference, and we must admit that it looks very promising as an alternative to OpenAI.
As we can read in the MPT model release note, it is:
- Licensed for the possibility of commercial use (unlike LLaMA).
- Trained on a large amount of data (1T tokens like LLaMA vs. 300B for Pythia, 300B for OpenLLaMA, and 800B for StableLM).
- Prepared to handle extremely long inputs thanks to ALiBi (we finetuned MPT-7B-StoryWriter-65k+ on up to 65k inputs and can handle up to 84k vs. 2k-4k for other open source AI models).
- Capable of fast training and inference (via FlashAttention and FasterTransformer).
- Equipped with highly efficient open-source training code via the llm-foundry repository.
It is also competitive when it comes to pricing – especially in cases when you want to train the model with your own training data sets.

The MPT-7B was shared with the three fine-tuned variants that demonstrate many different ways of building on the base model:
- MPT-7B-StoryWriter-65k+ – designed to read and write stories with super long context lengths (it accepts twice as long inputs as the GPT-4-32k!),
- MPT-7B-Instruct – a model for short-form instruction following (e.g., converting text input to a different format),
- MPT-7B-Chat – a chatbot-like model for dialogue generation, equipped for a wide range of conversational tasks and applications.
Used in: GPT4All
GPT-J & GPT-NeoX
GPT-J is a small 6B-parameter autoregressive model for text generation developed by EleutherAI. Its newest version, the GPT-NeoX, contains 20B parameters. The models are based on NVIDIA’s Megatron Language Model and have been augmented with techniques from DeepSpeed and additional optimizations. They can be fine-tuned using deepy.py or accessed as models pre-trained on The Pile, a dataset with 22 subsets of more than 800 GB of English texts.
Despite their small size, the GPT-J-6B and GPT-NeoX-20B models perform nearly identically to OpenAI’s Babbage and Curie models (GPT-3 family) in standard language modeling tasks.
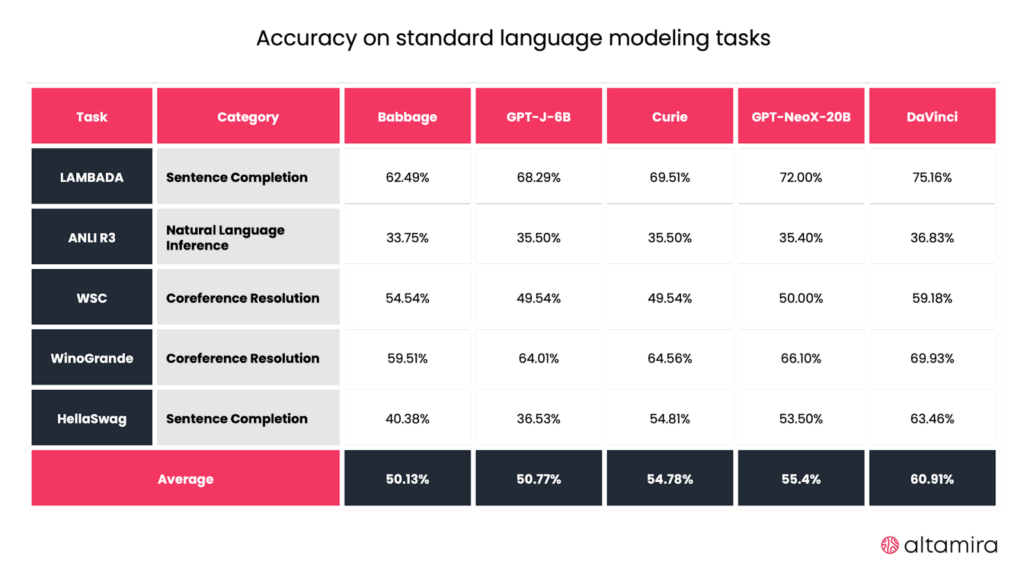
The models are completely free to use and, unlike LLaMA and OPT, allow commercial usage.
Used in: GPT4All
Dolly
Dolly is a public domain, instruction-following large language model that can be used in chatbots, summarize texts, and power basic search engines. But what’s probably most important – it is licensed for research and commercial use. As we can read in the official product release on the DataBricks blog:
Dolly 2.0 is a 12B parameter language model based on the EleutherAI pythia model family and fine-tuned exclusively on a new, high-quality human-generated instruction following dataset, crowdsourced among Databricks employees.
As Dolly 2.0 was fine-tuned on a human-generated instruction dataset (databricks-dolly-15k), it is not limited by the OpenAI API license – unlike all the models trained on a Stanford Alpaca dataset (the license prevents anyone from using AI-generated data to compete with OpenAI).
The dataset used for fine-tuning Dolly 2.0 contains 15,000 human-labeled prompt/response pairs. Just like the model itself, the databricks-dolly-15k dataset comes with Creative Commons Attribution-ShareAlike 3.0 Unported License. It allows anyone to use it, modify it, and create a commercial application on it.
Unfortunately, Dolly 2.0 has some substantial drawbacks. It hallucinates, only generates text in English, and can be toxic and offensive in its responses. As we can read in the Dolly model card:
In particular, dolly-v2-12b struggles with: syntactically complex prompts, programming problems, mathematical operations, factual errors, dates and times, open-ended question answering, hallucination, enumerating lists of specific length, stylistic mimicry, having a sense of humor, etc.
Let’s face it: it is not a state-of-the-art model (yet).
Read also: Top generative AI marketing tools: how they impact marketers’ work?

Top open-source alternatives to ChatGPT
Now, let’s take a look at some ChatGPT-like chatbots built with these Gen AI models.
Alpaca
Powered by: LLaMA
Alpaca was developed as a research project at Stanford University as an answer to a growing problem of AI models’ hallucinations and bias. As we can read in their papers:
“Instruction-following models such as GPT-3.5 (text-davinci-003), ChatGPT, Claude, and Bing Chat have become increasingly powerful. Many users now interact with these models regularly and even use them for work. However, despite their widespread deployment, instruction-following models still have many deficiencies: they can generate false information, propagate social stereotypes, and produce toxic language.
To make maximum progress on addressing these pressing problems, it is important for the academic community to engage. Unfortunately, doing research on instruction-following models in academia has been difficult, as there is no easily accessible model that comes close in capabilities to closed-source models such as OpenAI’s text-davinci-003.”
Stanford Alpaca claims that it can compete with ChatGPT, and anyone can reproduce it for less than 600$. Unfortunately, as it was created from LLaMa and fine-tuned with OpenAI’s InstructGPT, Alpaca “is intended only for academic research, and any commercial use is prohibited.”
Vicuna
Powered by: LLaMA
Vicuna was developed by the team from UC Berkeley, CMU, Stanford, and UC San Diego and trained by fine-tuning LLaMA on 70K user-shared conversations collected from ShareGPT with public APIs. Even though it uses fewer parameters than ChatGPT (13B compared to 175B), Vicuna was introduced as an “open-source chatbot impressing GPT-4 with 90% ChatGPT quality” and scored well in the performed tests.
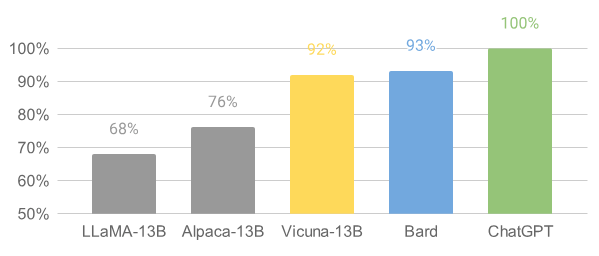
Built on top of Stanford’s Alpaca, Vicuna has a 4x extended max context (512 in Alpaca vs. 2048 in Vicuna), which significantly increases GPU memory requirements. It also lowers the cost of training:
- training the 7B model costs ~$140 (compared to Alpaca’s $500),
- and training the 13B model costs ~$300 (compared to ~$1K).
Unfortunately, just like in the case of Alpaca, the online demo is a research preview for non-commercial use only, as it uses the same base models and, therefore, must come under the same license.
GPT4All
Developed by Nomic AI, GPT4All was fine-tuned from the LLaMA model and trained on a curated corpus of assistant interactions, including code, stories, depictions, and multi-turn dialogue.
GPT4All is an open-source software ecosystem that allows anyone to train and deploy powerful and customized large language models on everyday hardware. It is optimized to run inference of 7-13 billion parameter LLMs on the CPUs of laptops, desktops, and servers. As explained by its creators:
The goal is simple – be the best instruction tuned assistant-style language model that any person or enterprise can freely use, distribute and build on.
GPT4All can answer questions about the world, serve as a personal writing AI assistant (write e-mails, documents, product descriptions, etc.), understand documents (write summaries and answers about their contents), or guide its users on easy coding tasks.
What is particularly important from the enterprise perspective is that GPT4All offers three different model architectures:
- GPTJ – Based on the GPT-J architecture
- LLAMA – Based on the LLAMA architecture
- MPT – Based on Mosaic ML’s MPT architecture
While the LLAMA-based models are available only under a non-commercial license, the GPTJ and MPT base models allow commercial usage, which makes GPT4All a good alternative to Chat GPT.
OpenAssistant
OpenAssistant is a very interesting project, released only a month ago, organized by Large-scale Artificial Intelligence Open Network (LAION) and more than 13,000 volunteers worldwide. Led by the vision to democratize Gen AI and prevent big corporations from monopolizing the LLM market, they plan to publish all their models, datasets, development and make the data-gathering process fully transparent.
This vision is especially important in the context of mistrust towards artificial intelligence. Open documentation limits the “black box effect” and makes the data more understandable.
OpenAssistant is an open-source replication of ChatGPT. It consists of 20 different models, which are available on Hugging Face. It was trained on OpenAssistant Conversations – a human-generated, human-annotated assistant-style conversation corpus consisting of 161,443 messages distributed across 66,497 conversation trees in 35 different languages, annotated with 461,292 quality ratings.
The source code and models are licensed under the Apache 2.0 license. It means that that end-users can utilize the model in any commercially licensed software or enterprise application for free.
Is there a true alternative to GPT? Final thoughts
The main problem with open-source alternatives to Chat GPT and GPT base models is that they are developed mainly as research projects. Their intended users are other researchers, academics, and hobbyists in natural language processing, machine learning, and artificial intelligence – and not commercial users. While the research works around these models and actively contributes to the development of the whole Gen AI field, the number of GPT competitors that can be used commercially as an alternative to GPT integration is limited and does not include the most powerful models.
Do the benefits of using open-source models outweigh their lower performance? In some cases – definitely. It is also worth highlighting that these models can be further developed and fine-tuned within organizations and achieve good results in specific use cases.
BONUS! Best AI chatbots: ChatGPT alternatives you can try yourself
In this article, we focused on the open-source foundation models only and we did not mention commercial alternatives to ChatGPT. However, as many of you asked about what is better than ChatGPT, we added a quick overview of its main alternatives as a bonus to this article. Let’s see what the best ChatGPT alternative for 2024 is!
Anthropic Claude
Claude is an advanced AI chatbot developed by Anthropic, designed to engage in natural language conversations and support content generation. In this way, it’s comparable to ChatGPT. Its latest verion, Claude 3, was released in 2024 and includes specialized models optimized for different tasks:
- Claude 3 Haiku for speed,
- Claude 3 Sonnet for balanced performance,
- and Claude 3 Opus for complex reasoning tasks.
The paid version of Claude supports an impressive context window of up to 100,000 tokens, allowing it to manage extensive conversations and analyze large documents effectively It is said to be particularly useful for programming, as it can generate code snippets, debug existing code, and provide explanations for programming concepts.
At the beginning, Claude was praised for its advanced reasoning which made it a solid alternative to ChatGPT Plus. The latter one, however, quickly caught up and perhaps surpassed Claude with the release of the o1 models family.
Want to learn more about Claude? Read about Claude 3.5 Sonnet vs. GPT-4o and GPT-4o mini — key differences
Microsoft Copilot
Microsoft Copilot is an AI tool integrated into various Microsoft applications, designed to enhance user productivity and streamline workflows. It utilizes advanced large language models, including OpenAI’s GPT-4o (yes, that’s right!), to provide intelligent suggestions, automate repetitive tasks, and support AI content creation and image generation across platforms like Microsoft 365, Windows, and GitHub. In this sense, it’s not really an alternative to OpenAI products. However, it does provide a different chat interface which may be a preferred option for some of the users.
Microsoft Copilot has a free plan that can be accessed through platforms like Windows, Microsoft Edge, and mobile apps. This version provides foundational capabilities, allowing users to interact with the AI assistant without any cost. For the paid versions (Copilot Pro and Copilot for Microsoft 365), with some more advanced features and integrations, users need to pay $20-$30.
Google Gemini
Gemini is an advanced AI chatbot (just like ChatGPT) developed by Google, designed to enhance user interaction across various applications and platforms. Its key features include multimodal interaction (which is something that Gemini and ChatGPT have in common), reasoning capabilities, and integration with Google Services. This last features seem to be the greatest advantage of Google in this competitive AI space.
Gemini seamlessly connects with various Google applications like Gmail, Docs, Maps, and more. This integration enables it to perform tasks such as reading emails aloud, summarizing documents, and even managing tasks across different apps without requiring users to switch between them.
Meta AI
Meta AI is an advanced AI tool developed by Meta, designed to enhance user interactions across its popular platforms, including Facebook, Instagram, Messenger, and WhatsApp. Launched in 2023, it leverages Llama 3, to provide personalized responses and facilitate seamless communication.
Users can chat with Meta AI in natural dialogue. It answers their queries and creates content such as text and photorealistic images based on user prompts.
As of 2024, Meta AI is available in 27 countries and in 7 languages: English, Spanish, Portuguese, French, German, Hindi, and Italian. According to Techcrunch, the company plans to release Meta AI in more countries in a gradual rollout, including the Middle East. After this rollout, Meta AI will be available in 42 countries and more than a dozen languages.

source: Techloy.com
Perplexity AI
The last great ChatGPT alternative in this comparison is Perplexity – an AI-powered conversational search engine. Launched in 2022, it combines the functionalities of traditional search engines with advanced generative AI capabilities to provide accurate and real-time answers to user queries. The free version utilizes a standalone large language model (LLM) based on GPT-3.5, while the paid version, Perplexity Pro, offers access to more advanced models like GPT-4 and Claude 3.5. Unlike ChatGPT, Perplexity AI combines the power of conversational AI with real-time search, delivering instant, source-backed answers, and reducing the risk of hallucinations.



{kind=link}