

The release of the new version of GPT models, GPT-4, has brought some extra attention to the already famous Open AI language models. No wonder! GPT-4 was introduced as OpenAI’s most advanced system, offering a wider range of applications and being able to solve complex problems with greater accuracy, thanks to its broader general knowledge and problem-solving abilities.
In this article, we compare three powerful language models: GPT-3, GPT-4, and GPT-3.5, which came in between the two groups of models. If you want to learn the similarities and differences between these AI models and what the cost of using them is, you are in the right place.
Table of Contents
What is OpenAI GPT-3?
GPT stands for generative pre-trained transformer, a type of large language model, and a prominent framework for generative artificial intelligence. GPT-3 is a large language model (LLM) developed by Open AI. It was trained on 175 billion parameters, released in June 2020 and quickly gained attention for its remarkable natural language generation capabilities.
GPT-3 comes in multiple base models with varying numbers of parameters and computational resources required. The most recognized ones are Ada, Babbage, Curie, and Davinci.

On March 15, 2022, Open AI released the latest version of GPT-3 called “text-davinci-003”. It was described as more capable than previous versions of GPT. It was already able to generate human-like text, produce factual responses in requested formats, answer, perform complex tasks, and solve difficult problems. Moreover, it was trained on data up to June 2021, making it way more up-to-date than the previous versions of the models (trained on data up to Oct 2019). Eight months later, in November 2022, OpenAI started to refer to this language model as belonging to the “GPT-3.5” series. But let’s skip the timeline.
What is GPT-3.5?
As for today, we have 5 different model variants of different capabilities that belong to the GPT-3.5 series. Four of them are optimized for text-completion tasks, and one is optimized for code-completion tasks.
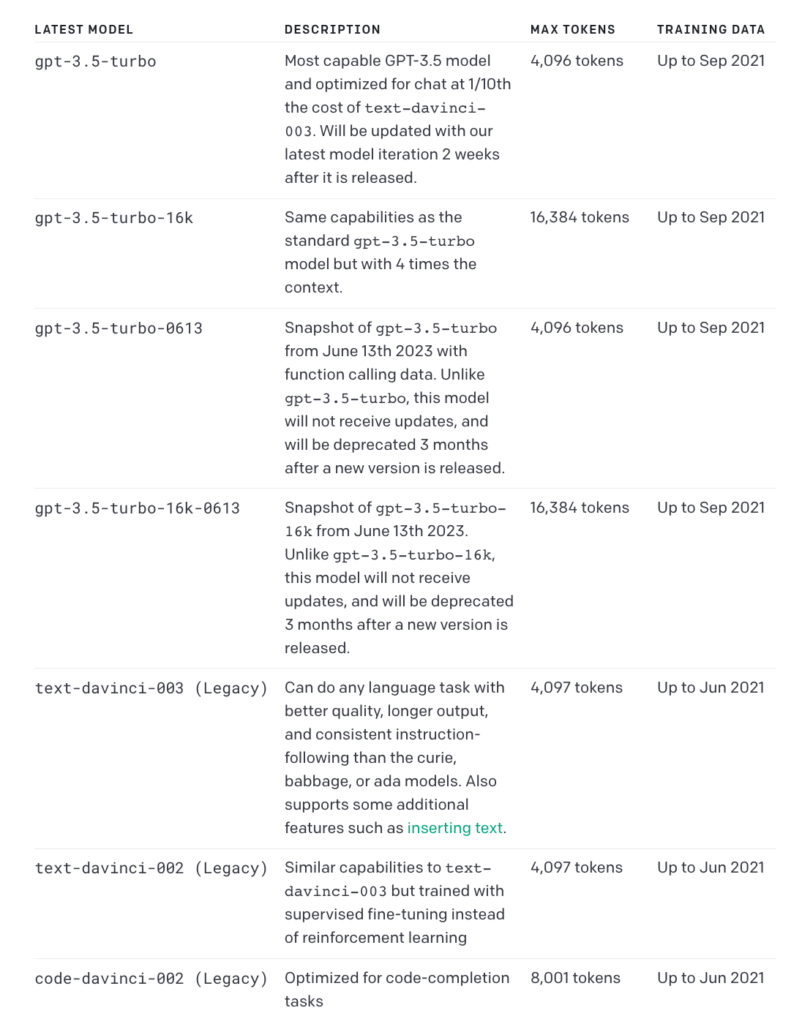
It has capabilities similar to those of the GPT-3 (including generating text, text summarization, and other “traditional” completion tasks) but is also optimized for chat completions. It is able to take text input, answer questions using informal language, and handle other content creation tasks.
The latest model version of the GPT-3.5, the gpt-3.5-turbo, was released on March 1, 2023 – and it has instantly caused a spike in interest in GPT-3.5. Just to warm the audience up before the release of GPT-4.
What is OpenAI GPT-4?
GPT-4 is the most recent, and most advanced, version of the Open AI language models. Introduced on March 14, 2023, it is said to be the new milestone in deep learning development. Rumors claim that GPT-4 has 1.76 trillion parameters.
GPT-4 is said to be able to generate more factually accurate statements than GPT3 & GPT-3.5, ensuring greater reliability and trustworthiness. Also, unlike its predecessors, it’s a large multimodal model, meaning it can accept images as inputs and generate captions, classifications, and analyses. Last but not least, it can create more creative content. According to OpenAI, “it can generate, edit, and iterate with users on creative and technical writing tasks, such as composing songs, writing screenplays, or learning a user’s writing style.”
For now, in March 2023, the GPT-4 comes in two model variants:
gpt-4-8Kgpt-4-32K
which differ by the size of their size of the context window. Even though GPT-4 is already in commercial use, most users will need to wait some time until they get access to GPT4 API and build their own GPT-4-powered applications and services.
Is it worth waiting? Let’s see!
GPT-4 vs. GPT-3 and GPT-3.5 – key differences
When asked to compare GPT-4 to GPT-3, Greg Brockman, one of the co-founders of Open AI and its president, had one word: Different. As he has told Techcrunch:
There’s still a lot of problems and mistakes that [the model] makes … but you can really see the jump in skill in things like calculus or law, where it went from being really bad at certain domains to actually quite good relative to humans.
Let’s try to elaborate on this a bit further. Especially that the GPT-4 research published by Open AI reveals surprisingly many details about the new models.
GPT-3 and GPT-4 model’s capabilities
One of the biggest differences between GPT-3 & GPT-4 is their capabilities. GPT-4 is said to be more reliable, creative, collaborative, and able to handle much more nuanced instructions than GPT 3.5.
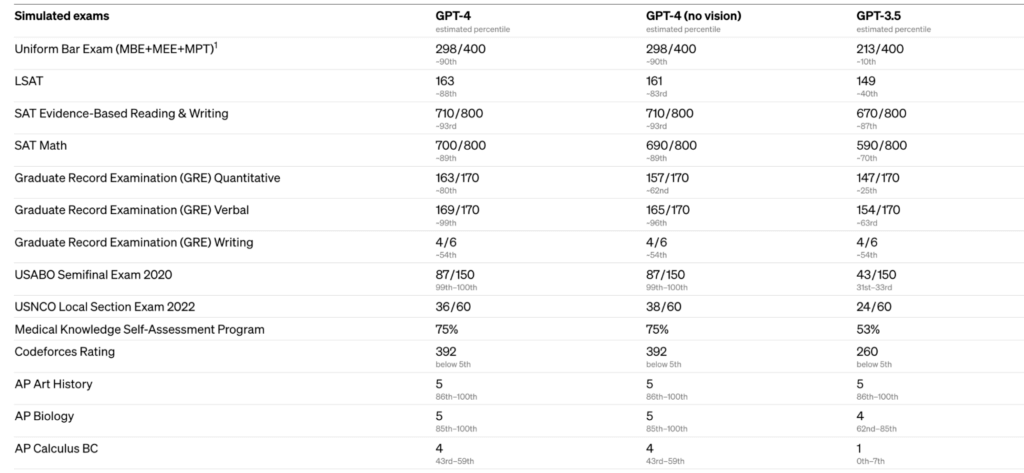
To understand the distinction between the two models, Open AI developers have tested them on different benchmarks. The benchmarks included simulating exams that were originally designed for humans.
We proceeded by using the most recent publicly-available tests (in the case of the Olympiads and AP free response questions) or by purchasing 2022–2023 editions of practice exams. We did no specific training for these exams. A minority of the problems in the exams were seen by the model during training, but we believe the results to be representative.
(source: OpenAI)
The results are stunning!
While GPT-3 scored only 1 out of 5 on the AP Calculus BC exam, GPT-4 scored 4. In a simulated bar exam, GPT-4 passed with a score around the top 10% of test takers. GPT3.5 – the most advanced version of the GPT-3 series – was at the bottom 10%.
Moreover, GPT-4 is… a true polyglot. While GPT’s English proficiency was already high in the GPT-3 and 3.5 versions (with shot accuracy at 70.1%), its accuracy in the newest version increased to over 85%. Actually, it speaks 25 languages better than its ancestors spoke English – including Mandarin, Polish, and Swahili. That is pretty impressive, considering that most of the existing ML benchmarks are in English.
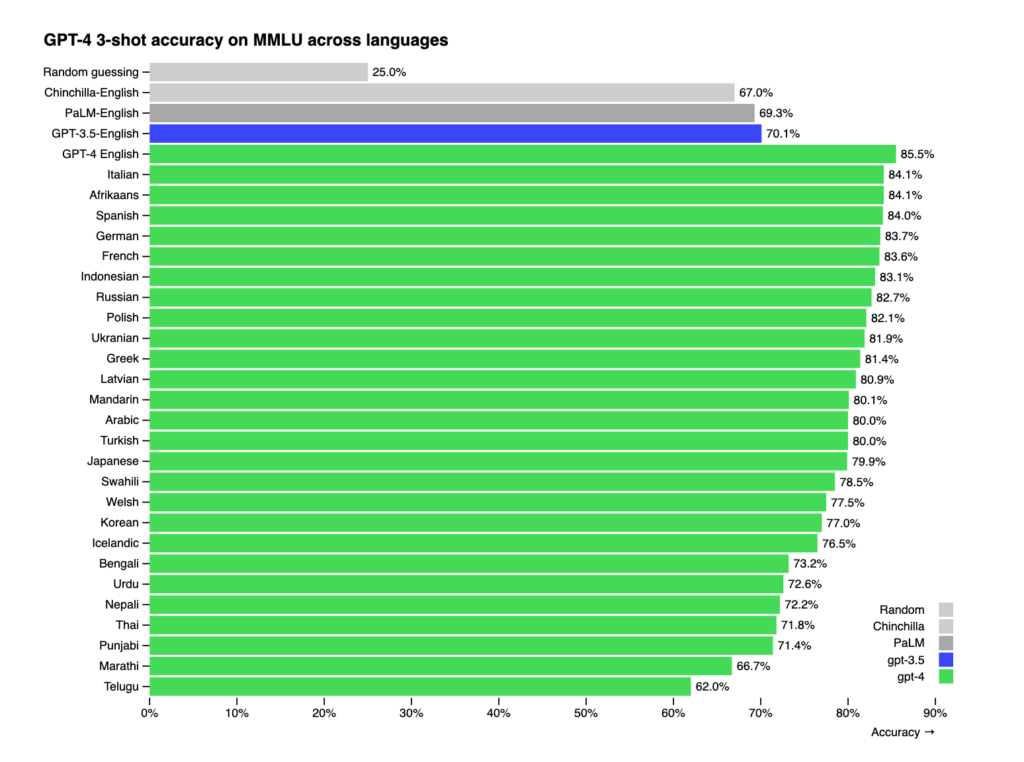
If that wasn’t enough, GPT-4 can process much longer text at a single request—all thanks to the higher context length.
Token limits in GPT-3 & GPT-4
Context length is a parameter used to describe how many tokens can be used in a single API request. The original GPT-3 models released in 2020 set the max request value at 2,049 tokens. In the GPT-3.5, this limit was increased to 4,096 tokens (which is ~3 pages of single-lined English text). GPT-4 comes in two variants. One of them (GPT-4-8K) has a context length of 8,192 tokens, and the second one (GPT-4-32K) can process as much as 32,768 tokens, which is about 50 pages of text.
| Open AI model’s version | GPT-3 (ada, babbage, curie, davinci) | GPT-3.5 (gpt-3.5-turbo, gpt-3.5-turbo-0301,text-davinci-003, text-davinci-002)* | GPT-4-8K | GPT-4-32K |
| Context length (max request) | 2,049 | 4,096 | 8,192 | 32,768 |
| Number of English words | ~1,500 | ~3,000 | ~6,000 | ~24,000 |
| Number of single-spaced pages of English text | 3 | 6 | 12 | 50 |
That being said, we can think about all the new use cases for GPT-4. With their ability to process 50 pages of text, it will be possible to use the new models to create longer pieces of text, analyze and summarize larger documents or reports, or handle conversations without losing context. As presented by Greg Brockman in the interview for Techcrunch:
Previously, the model didn’t have any knowledge of who you are, what you’re interested in and so on. Having that kind of history [with the larger context window] is definitely going to make it more able … It’ll turbocharge what people can do.
But that’s not the end because in addition to processing text inputs, GPT-4 can interpret other input types as well.
Text and image inputs in GPT 4 and GPT 3
While the GPT-3 and GPT-3.5 models were limited to one type of input (text; or code – to be precise), the GPT-4 accepts an extra input type: images. Specifically, it can produce text outputs out of text or image inputs.
Depending on what you ask the GPT-4 model to do, it can generate captions, classify visible elements, or analyze the image. Among the examples presented in the GPT-4 research documentation, we can see the models analyzing the graphs, explaining memes, and even summarizing the papers that consist of text and images. We must admit that GPT-4’s image understanding abilities are impressive. Just take a look!

The ability to process images, combined with the higher token limits, opens up new possibilities for using GPT-4 – from academic research to personal training or shopping assistants. Don’t get too excited, though! It may still take some time until you can make use of this new skill of GPT-4. As we can read on the Open AI site, image inputs are still a research preview and not publicly available.
Defining the context of GPT-4 & GPT-3 conversation
Another huge difference between GPT-3 and GPT-4 is how we can determine the model’s tone, style, and behavior.
In the newest version of GPT, it is possible to provide the model with the instructions on an API level by including so-called “system” messages (within bounds described in detail in the Open AI’s Usage policy). These instructions set the tone of the messages and describe how the model should behave (e.g., “You never give the student the answer but always try to ask just the right question to help them learn to think for themselves”). Additionally, they establish boundaries for GPT-4’s interactions, being able to act as “guardrails” to prevent GPT-4 from changing its behavior on the user’s request. Just like in the following example:

As you can see, the GPT-4 stays within its role—defined in the system message—despite the user’s requests.
To some extent, we could already experience a similar model’s ability in the recently released GPT-3.5-Turbo. By defining the model’s role in a system with text prompts, we could get a different response.How useful for the virtual assistants! See how the message differs depending on who the GPT is pretending to be:

Until March 2023, when the GPT-3.5-Turbo was released, it was not possible to provide the model with the system message. The context information needed to be given within the prompt and could easily change throughout the conversation.
The new GPT-4’s ability allows it to be more consistent in its behavior and more adjustable to external specifications (e.g., your brand communication guidelines).
Cost of using GPT-4 vs. GPT-3
Of course, it all comes at a price. While the GPT-3 models cost from $0.0004 to $0.02 per every 1K tokens, and the newest GPT-3.5-Turbo came 10x cheaper ($0.002 per 1K tokens) than the most powerful GPT davinci model, the cost of using GPT-4 leaves no illusions: if you want to use the most advanced language models, you will need to pay extra.
The GPT-4 with an 8K context window will cost $0.03 per 1K prompt tokens and $0.06 per 1K completion tokens. The GPT-4 with a 32K context window, on the other hand, will cost $0.06 per 1K prompt tokens and $0.12 per 1K completion tokens.
If processing 100k requests with an average length of 1500 prompt tokens and 500 completion tokens costed $4,000 with text-davinci-003 and $400 with gpt-3.5-turbo, with GPT-4, it would cost $7,500 with the 8K context window and $15,000 with the 32K context window.
Not only is it expensive, but also more complicated to calculate. That’s because the cost of the prompt (input) tokens differs from the cost of completion (output) tokens. If you remember our GPT-3 pricing experiment, you already know that estimating the token usage is difficult as there is a very low correlation between input and output length. With the higher cost of the output (completion) tokens, the cost of using GPT-4 models will be even less predictable.
*Note that in this article, we do not focus on ChatGPT, which uses GPT-3.5 in its free version, and GPT-4 in ChatGPT Plus.
Fine-tuning of the OpenAI language models
Remember how we defined the context in the system message for the GPT-4 and GPT-3.5-Turbo? Fine-tuning is basically a workaround method to define the model’s tone, style, and behavior and customize the models to a specific application.
To fine-tune the model, you train it on many more examples than the prompt can fit. Once a model is fine-tuned, you don’t need to provide examples in the prompt. This saves costs (every 1K tokens counts!) and enables lower-latency requests. Sounds great, doesn’t it? It’s a pity, though, that the only Open AI models that are currently available to fine-tune are the original GPT-3 base models (davinci, curie, ada, and cabbage).
Read also: Top generative AI marketing tools: how they impact marketers’ work?
GPT errors and limitations
When different rumors about GPT-4 came out (e.g., the one regarding the number of parameters it uses), Open AI’s CEO commented that
The GPT-4 rumor mill is a ridiculous thing. I don’t know where it all comes from. People are begging to be disappointed, and they will be. (…) We don’t have an actual AGI, and that’s sort of what’s expected of us.
While it’s hard to call GPT-4 disappointing, considering its creativity and amazing capabilities, it’s important to note its limitations. As we can read in the product research documentation, they didn’t change that much compared to GPT-3 and 3.5.
Just like its predecessors, GPT-4 lacks knowledge of events that occurred after September 2021. That’s because this is how far its training data gets. Moreover, no matter how smart chatbots like ChatGPT seem to be, it is still not fully reliable – even when powered with a large dataset of GPT-4. Even though it is claimed to significantly reduce hallucinations relative to previous models (scoring 40% higher than GPT-3.5 in their internal evaluations), it still “hallucinates” facts and makes reasoning errors. It can still generate harmful advice (although it is way more likely to refuse to answer), buggy code, or inaccurate information, and because of that, it shouldn’t be used in areas with high error costs.
Read also: Open-source versus OpenAI. 8 best open-source alternatives to GPT
GPT-3 vs. GPT-4 comparison – key takeaways
As Open AI’s most advanced system, GPT-4 outperforms older versions of the models in almost every area of comparison. It is more creative and more coherent than GPT-3. It can process longer pieces of text or even images. Finally, it has higher accuracy and it’s less likely to make “facts” up. Thanks to its capabilities, it can handle more complex tasks and creates many new possible use cases for generative AI development.
Does it mean that GPT-4 will replace GPT-3 and GPT-3.5? Probably not – or at least not yet. Even though GPT is more powerful than the previous versions of GPT models, it is also way more expensive to use. In many use cases where you don’t need a model to process multi-page documents or “remember” long conversations, the capabilities of GPT-3 and GPT-3.5 will be just enough.





{kind=link}