
After the infamous ChatGPT bug, which leaked users’ conversation histories along with some payment-related information, the topic of generative AI data safety came into question.
Soon after that, OpenAI launched a bug bounty program, offering cash rewards of up to $20000 for disclosing security vulnerabilities in its systems. At the same time, the Italian National Authority for Personal Data Protection temporarily banned ChatGPT, citing privacy violations. And while Italy was the first Western country to act against ChatGPT, it was already banned across some organizations such as Bank of America, Goldman Sachs Group, and Amazon – to name only a few.
Are data security and privacy something to worry about when you’re thinking about generative AI adoption? How to take advantage of this breakthrough technology without putting your data at risk? In this article, we analyze how ChatGPT and other generative AI models approach data privacy issues. We will also take a look at different ways of making your data safe while using generative AI.
OpenAI Data Policy
The first thing to understand about OpenAI security is the difference between OpenAI API users and non-API users.
OpenAI non-API services include ChatGPT and DALL-E. Everybody can access them, no engineering skills are required, but you can’t manipulate the model, fine-tune it or feed it with your own datasets. OpenAI API services, on the other hand, include the GPT-3 (ada, babbage, curie, davinci), GPT-3.5 (text-davinci-003, gpt-3.5-turbo), and GPT-4 models. They can be accessed through the OpenAI Platform and allow their users to set different model parameters, import their own datasets, and add some tweaks to the models – and therefore require more proficiency in working with generative AI.
Even though ChatGPT is powered by the GPT models, they are separate services, and as such – they have different data policies.
ChatGPT security & data policy
If you use ChatGPT or DALL-E, you agree that OpenAI may use the data you provide as training data to improve their models.
For non-API consumer products like ChatGPT and DALL-E, we may use content such as prompts, responses, uploaded images, and generated images to improve our services.
Moreover, the data you share may also be provided to 3rd party companies, including:
- providers of hosting services, cloud services, and other information technology services providers,
- event management services,
- email communication software and email newsletter services,
- web analytics services.
While OpenAI claims to use only a small sampling of data per customer and to remove any personally identifiable information from data that is used to improve model performance, you probably shouldn’t share any sensitive data with the ChatGPT. Unless you specify that you don’t want to save your chats and use them for model training.
Until recently, the only way to prevent OpenAI from using your chat history to train their models was to opt out by contacting OpenAI through the special form. However, the recent issue with the Italian government temporarily banning ChatGPT has resulted in introducing changes to the area of data protection for ChatGPT users. As we can read in OpenAI’s recent blog post (April 25, 2023):
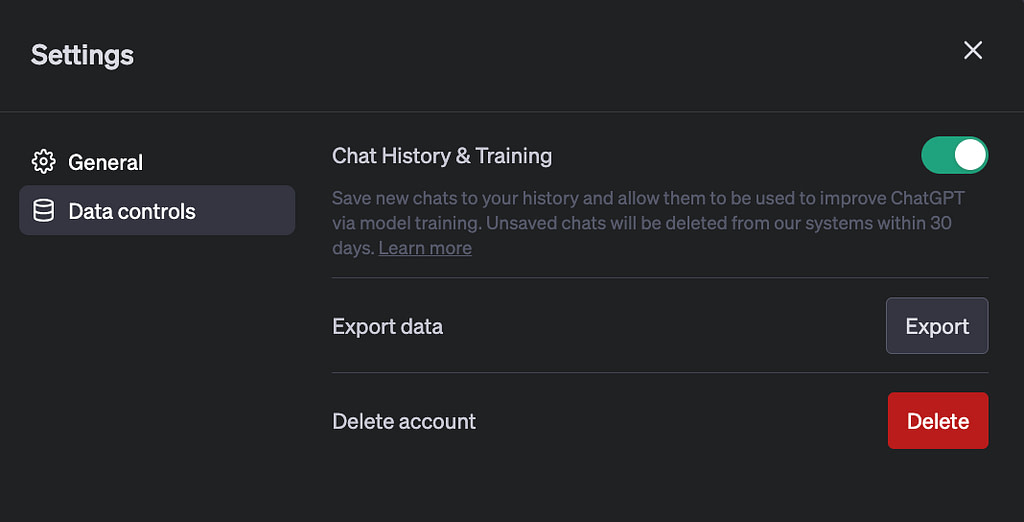
We’ve introduced the ability to turn off chat history in ChatGPT. Conversations that are started when chat history is disabled won’t be used to train and improve our models and won’t appear in the history sidebar. These controls, which are rolling out to all users starting today, can be found in ChatGPT’s settings and can be changed at any time. We hope this provides an easier way to manage your data than our existing opt-out process. When chat history is disabled, we will retain new conversations for 30 days and review them only when needed to monitor for abuse before permanently deleting.
Right now, ChatGPT can easily manage their data in their account settings.
Read also: 8 Best Open-Source Alternatives to GPT
GPT API data policy
Still, if you want your data to be secure, you should consider using GPT API. As the GPT API is only available over Transport Layer Security (TLS), all the user requests and responses are encrypted. Moreover, the OpenAI API is SOC 2 Type 2 compliant (*SOC 2 is a security framework developed by the American Institute of Certified Public Accountants that specifies how organizations should protect customer data from unauthorized access, security incidents, and other vulnerabilities) and was audited by an independent third-party auditor in 2017.
As we can read in the OpenAI API data usage policies:
OpenAI will not use data submitted by customers via our API to train or improve our models, unless you explicitly decide to share your data with us for this purpose.
In other words, the data you submit for fine-tuning will only be used to fine-tune your model. Unless you decide to opt in to share that data.
Additionally, the newest GPT models (GPT3, GPT-3.5, and GPT-4) can be accessed through Azure OpenAI Service, which runs on the Azure global infrastructure and provides its users with role-based access control (RBAC) and private network connectivity. The data stored in Azure Storage is encrypted at rest by Microsoft Managed keys within the same region as the resource and logically isolated with their Azure subscription and API Credentials. Uploaded files can be deleted by the user. As promised by its creators, “OpenAI Service brings together OpenAI API and Azure enterprise-level security, compliance, and regional availability.”
To sum it up: If you don’t want your data to be used for model training, use OpenAI API products. While ChatGPT and DALL-E are very useful in certain use cases (and, let’s admit it – simply fun to play with), it is better not to share too much of your private data with them. If data security is critical for your organization, you may also consider using Azure OpenAI Service and benefit from Microsoft’s built-in security controls.
Data security in other generative AI models
And what about the alternatives to OpenAI models? Let’s see how data privacy issues look in other generative AI models: Bard for text-to-text and Midjourney for text-to-image operations.
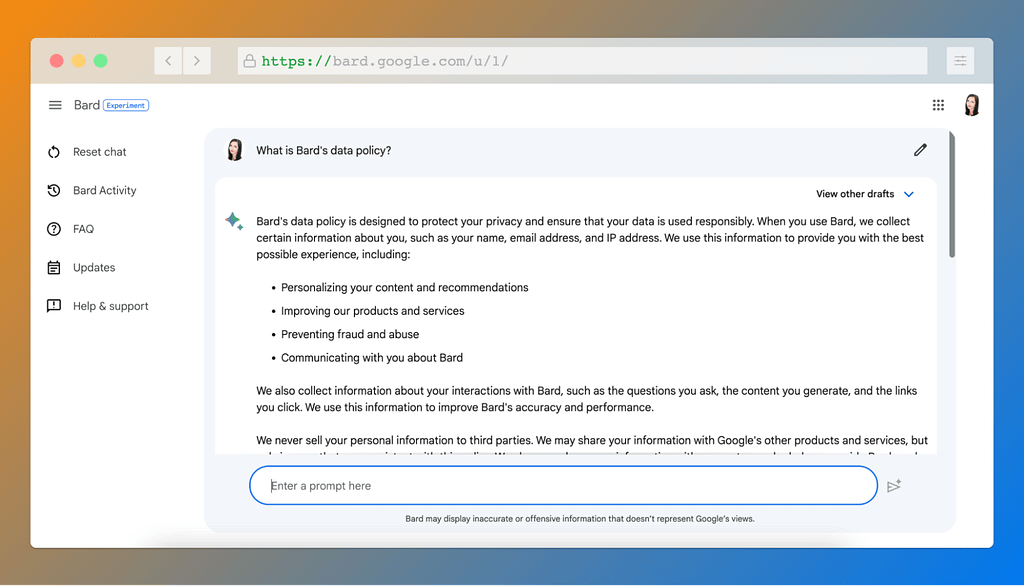
Text-to-text: Bard data policy
All Google products are recognized for their strong security features that continuously protect users’ information. And their flag generative AI product is no different.
The chat history of every Bard user is encrypted using industry-standard encryption protocols, which protects it from being intercepted or read by unauthorized individuals. It is stored in secure locations which are protected by physical security guards and access control systems. It is also regularly monitored for security threats, and – last but not least – it can be deleted at any time.
However, just like with OpenAI’s ChatGPT, you need to take some extra precautions if you don’t want your data to serve as training material for the models.
By default, chat history is stored and used to develop the model. Bard can learn from your interactions (the questions you ask, the content you generate, and the links you click) and improve upon them. As explained by Bard (no worries, we checked that it’s consistent with its Privacy Policy):
We select a subset of conversations and use automated tools to help remove personally identifiable information. The conversations that are stored are selected randomly and are not associated with any specific user. They are also anonymized so that no personal information can be identified.
The sampled and anonymized data can be kept for up to 3 years, separately from your Google Account.
What if you do not want your chat history to be used for training? You can simply delete chat history after you are finished using Bard or opt out of data collection. To do so, you need to:
- Go to bard.google.com.
- At the top left, select [Menu] and then [Bard Activity] and then the “Bard Activity” card.
- Turn off Bard Activity.
You can also choose to use Bard in an incognito window, which will prevent your chat history from being stored.
To sum it up: Your chat history and other data that you share with Bard are as safe as with any other Google products. By default, your prompts and generated answers may be sampled and used for model training. However, if you don’t want Bard to use your chat history to improve its results, use it in an incognito mode or make sure you opt out of data collection.
In general, the data policies of the two most recognized text-to-text models do not differ that much. If you use their free products, your chat history is collected and used to improve models by default. Yet, you can always opt-out. Is it the same with the text-to-image models?

Text-to-image: Midjourney data & privacy policy
Midjourney collects data about your use of our service, including the prompts and responses you use to generate images to improve the service, provide you with personalized recommendations, and comply with applicable laws. At this point, it is not that different from ChatGPT or Bard. However, as an open community, Midjourney poses another threat to your data security.
In the Midjourney’s Terms of Service, we can read that:
If You are not a Paid Member, You don’t own the Assets You create. Instead, Midjourney grants You a license to the Assets under the Creative Commons Noncommercial 4.0 Attribution International License.
If you decide to play with Midjourney, your images are publically viewable and remixable, meaning that other users are allowed to use and modify images and prompts that you’ve posted. So even though it is less likely that you accidentally share any sensitive information when generating an image, you should keep in mind that the images that Midjourney creates based on your prompt – hope it’s not your new logo! – can be modified and used by other users. To bypass some of these public sharing defaults, you may purchase a “Pro” plan with a so-called “Stealth” feature. In such a case, Midjourney agrees to “make best efforts not to publish any Assets you make” (Terms of use, access May 8, 2023). Whatever “best efforts” may be, hope they’re enough to keep your data safe.
How to secure your data when using ChatGPT and other generative AI models?
While the providers of the most popular generative AI models take precautions to keep their users’ data secure, sometimes it’s just not enough. The question arises: what can you do to secure your data when using such models? May it be the GPT, Bard, Midjourney, or any other generative AI.
If you use non-API generative AI products, the best thing you can do is… not to share sensitive information. Educate your employees, prepare detailed guidelines with the allowed and prohibited use cases of generative AI, and – if it’s possible, like with ChatGPT – ensure that every user turns the Chat history & training off in their settings.
More options come when you use generative AI models through their API.
In such a case, you have more control over how your data is processed. Moreover, you can run models through dedicated cloud-based services, such as the aforementioned Azure OpenAI Service, which runs on the Azure global infrastructure and provides its users with role-based access control, data encryption, and private network connectivity.
Additionally, if the recent rumor about Foundry turns out to be true, it may soon be possible to use GPT models on dedicated servers and benefit from additional safety measures such as confidential computing.

Confidential computing & cloud enclaves
Confidential computing is a technology that isolates sensitive data and code from the underlying hardware and operating system. This means that even if the hardware or operating system is compromised, the data and code will remain secure.
There is a specific type of confidential computing that is implemented in the cloud – cloud enclaves. While in other types of confidential computing, sensitive data and code are isolated from the underlying hardware and operating system, cloud enclaves enable us to isolate sensitive data and code also from the cloud provider and other users of the cloud.
Very often, they come as a part of service offered by cloud providers, for example:
- Google Cloud Platform (GCP): Confidential VMs, Confidential GKE Nodes, and Confidential Ledger.
- Amazon Web Services (AWS): Nitro Enclaves, AWS Lake Formation, and AWS SageMaker Private Endpoints.
- Microsoft Azure: Azure Confidential VMs, Azure Confidential Containers, and Azure Confidential Ledger.
In general, such solutions are used for applications that require high levels of security. By using confidential computing and cloud enclaves, different organizations can use their data to train the same models without really sharing that data. Just like in a healthcare use case example shared by Reluca Ada Popa in the recent episode of The Robot Brain Podcast:
Let’s say two hospitals don’t want to share their confidential data with each other, but by putting their data together, they can obtain a better disease treatment or diagnosis. With confidential computing, they know that their data will not be visible to anybody – it’s going to stay protected, encrypted – but still be able to run their machine learning. It really enables this kind of collaboration and hence — building better AI models.
Although these methods are well-known in the field of analytical AI, they are not so widely applied (yet) in generative AI.
Is your data safe with generative AI? Key takeaways
When we think about generative AI adoption, tension seems inevitable. Users of generative AI models are concerned about their data privacy, and, at the same time, they want to have better, more advanced models. To train such models, however, training data is required. Is it possible to break this vicious circle? Luckily, it is.
If you’re implementing GPT or other generative-AI-powered solutions in your organization, make sure to:
- Conduct a thorough risk assessment to identify potential security risks and determine the best ways to mitigate them.
- Read data policies carefully. If you want to use a model to process your personal information or your company’s sensitive data, make sure it’s not used to train the models. Sometimes, it’s just changing the account settings, sometimes, it may require taking an extra effort and contacting service providers.
- Implement strong security policies and procedures to protect against unauthorized access and data breaches. If possible, use data encryption methods and store your data in a secure location.
- Provide employee training on best practices for data security, including how to identify potential security risks and how to follow company security policies and procedures.
- Regularly review and update security measures to ensure they are effective in protecting against the latest threats.
Not sure how to secure your data in your next generative AI project? We will help you with that.
Complete the form below, and let’s talk about your challenges.