
Generative AI has been doing a great job keeping its top spot on nearly everybody’s tongues for the past few months. Last week was no different. While some got into a discussion about a Stanford researchers’ study showing that GPT-3.5 and GPT-4 may be getting dumber, Meta stole the spotlight by releasing its brand new LLM, Llama2, developed in cooperation with Microsoft.
This launch was particularly exciting as Llama’s 2 creators surprised the tech world by announcing that the model is fully open-source and free for both research and commercial purposes (while its previous version was open only for research).
And naturally, in the light of GPT’s intelligence being questioned, this premiere made some of us wonder: Who wins in the duel between Llama 2 and GPT-4? Is Llama 2 better than GPT-4? Or GPT-3.5? Or it’s not even anywhere near? Or… maybe it depends?
Let’s take a closer look at all three models to find answers to those questions!
Table of Contents

What are GPT-3.5 and GPT-4?
As you’re probably well aware, GPT-3.5 and GPT-4 belong to the family of large language models (LLMs) developed by OpenAI. They’re both paid (you can learn more about it in our article explaining GPT pricing) and available through OpenAI API.
GPT-3.5 overview
Released in March 2022, it was primarily referred to as an updated version of GPT-3. With time, however, its creators started to call it as we know it today — and released several other variants (see the table below) that became part of the GPT-3.5 family.
The most advanced (and, according to OpenAI, also the most cost-effective) of them, gpt-3.5-turbo, is the one that powers up the free version of ChatGPT.

GPT-4 overview
GPT-4, released in March 2023, is the latest & the most capable of OpenAI’s models and the most powerful LLM out there (at least for now). Its main distinguisher is the ability to process both text and image inputs, making it useful for many more purposes than its predecessors. However, it is also the most expensive LLM available.
GPT-4 is available in two variants — gpt-4-8K (powering Chat GPT Plus) and gpt-4-32K.

Okay, but considering I just said, “it is the most powerful LLM out there,” doesn’t it mean that OpenAI’s GPT-4 is better than Llama 2, so we can just finish this article right here and move on? Well, it’s not that simple— and we’ll get to that in a minute. But first, let’s take a look at the overview of Llama 2.
(By the way, if you could use more information about GPTs, you should take a look at our article comparing GPT-3, GPT-3.5, and GPT-4.)
What is Llama 2?
Llama 2, released on July 18, 2023, is a second generation of LLaMA, an LLM developed by Meta. The new model, however, results from cooperation between Meta and Microsoft, which has also partnered with OpenAI and actively supports the development of the GPT family.
Llama 2 is available in three sizes — 7B, 13B, and 70B parameters, as well as in pre-trained and fine-tuned variations. Meta also trained a 34B parameter version, but it was never released. Some speculate it’s due to safety-related reasons, as one of the charts in the research paper on Llama 2 model shows 34B as an outlier on a graph presenting “safety human evaluation results.”
Unlike GPTs, Llama 2 is an open-source LLM that is free for research and business use.
Read also: Is Llama 3 Better Than GPT-4? Llama 3 vs. GPT-4 vs. GPT-4o Comparison

Is Llama 2 better than ChatGPT?
First, let’s emphasize the fundamental difference between Llama 2 and ChatGPT. While the former is a large language model, the latter is a tool powered by an LLM. Hence, the real question is whether Llama 2 is better than GPT-3.5 (to be precise, the turbo version, as we refer to Chat GPT). Or, in the case of ChatGPT Plus, GPT-4.
The thing is, in both cases, the answer is: it depends. Let me explain.
Llama vs. GPT architecture: is Llama2 better than GPT-4 and GPT-3.5?
There are several differences between Meta’s Llama 2 and OpenAI’s GPTs, with the bottom line that GPTs are much bigger than Meta’s model. The thing is — the size itself isn’t enough to settle the debate about whether Meta’s model is better or worse than OpenAI’s flagships.
Each of those language models has different strengths and weaknesses, and their performance in natural language understanding, processing, and generation differs depending on the task. Hence, choosing the best model for your project greatly depends on what you plan to use it for and what requirements come along with that use case.
Before we get to examples, take a look at the table below:

Llama 2, GPT-4 and GPT-3.5 — model size
As already mentioned, OpenAI’s flagship models (with GPT-4 on top) are bigger than Meta’s model. The problem is, it’s not clear exactly how big they are. For reasons known probably only to OpenAI itself, the company didn’t reveal how many parameters GPT-3.5 and GPT-4 have — and doesn’t seem to plan on doing so.
According to the article by Semafor and a few other sources, GPT-4’s parameter count is 1 trillion. However, George Hotz estimated it to 1,76 trillion — claiming that OpenAI GPT-4 is based on a Mixture of Experts (MoE) architecture consisting of eight models, 220B parameters each.
Many AI experts seem to agree that Hotz’s theory is very likely true. But as OpenAI is the exact opposite of “open” on this, let’s assume that GPT -4’s parameters count is somewhere between 1 and 1,76 trillion.
And what about GPT-3.5? I wish I could tell you it’s less complicated, but sadly — no. Among several considerably reliable sources, some speak of 175 billion parameters (e.g., Techopedia), while others (e.g., Ankur’s Newsletter) mention 154B. Again, considering we’re missing OpenAI’s voice on that, let’s assume 154–175 billion is the most likely range for GPT-3.5.
The only clear information here comes from Meta: we know there are three variants of its newest model available — 7B, 13B, and 70B. Considering all the above, it looks like the largest member of the Llama 2 family is ~40–45% smaller than GPT-3.5 and ~96% smaller than GPT-4.
Which brings us to the question: does it mean Llama is the “worst” of all three?
Learn from the hands-on experience of Caju AI!
Llama 2 and GPT models — accuracy & task complexity
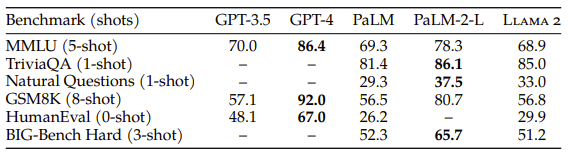
Not necessarily! Although one might think the size of Llama makes it less accurate than GPTs, the 5-shot MMLU benchmark shows that Meta’s model performs nearly on par with GPT-3.5.
Similar results in relation to GPT-3.5 were shown in Meta’s human evaluation study described in their research paper on their model (mentioned and linked earlier in the article). The study was run on the models’ pre-trained versions — Llama 2-Chat 70B and ChatGPT, as well as a few other LLMs.
It consisted of 4000 prompts (both single-turn and multi-turn) that human evaluators used to rate the competing models on helpfulness and safety. Llama-2-Chat 70B passed the helpfulness evaluation on par with GPT-3.5 — precisely, with a 36% win rate and 31.5% tie rate.
Such good results relative to GPT-3.5 may be due to the fact that Llama 2 uses a novel technique called Ghost Attention (GAtt, developed by Meta) that improves the model’s ability to control dialogue over multiple turns. In simpler terms, it allows the model to focus on specific parts of the conversation history when generating a response — making its outputs more accurate.
Sadly, GPT-4 wasn’t included in Meta’s study. However, it significantly outperforms both Llama 2 and GPT-3.5 on the 5-shot MMLU benchmark, remaining the best choice for most complex and “mission-critical” tasks, as well as those requiring the highest level of creativity.

Llama 2 vs. GPT-4 vs. GPT-3.5 — creativity
Even though all three models thrive in natural language processing and natural language generation (and all can hold conversations in multiple languages), their creativity levels differ — mostly due to their sizes and complexity — and GPT-4 wins in this duel.
When asked to generate a poem, it uses the most sophisticated vocabulary & metaphors and the widest array of expressions, which makes its output sound like written by a rather experienced writer. On the flip side, the work of Llama 2, although correct in the context of the prompt, falls far from GPT-4 and resembles more of a school assessment level.
As it falls somewhere between task complexity and creativity, let’s also mention models’ coding skills here. Although in MMLU and GSM8K benchmarks Llama 2 hits nearly the same scores as GPT-3.5, in a HumanEval (coding) benchmark, it ranks way behind it (29,9% vs. 48,1%) — not no mention GPT-4, which outperforms Llama 2 more than twice (67%).
Llama 2 vs. GPT-4 vs. GPT-3.5 — token limit
As you can see in the table above, Llama 2 has the same token limit as the base variant of GPT-3.5-turbo, while the base GPT-4 doubles them. Remember, though, that both GPTs are available in variants with even bigger token limits. What does it mean?
The longer inputs and outputs you expect in your use care, the bigger the token limit you need. In other words, if you want your software to process lengthy documents, Llama 2 would be the least recommended choice.
Llama 2, GPT-4 and GPT-3.5 — modalities
This one is pretty simple. Of our three competitors, GPT-4 is the only one able to process (static) visual inputs. Hence, if you want your software to have such a skill — GPT-4 is your fighter. GPT-3.5 and Llama 2 are text only.
If you want to learn more about GPT-4 capabilities and potential use cases utilizing its image processing capabilities, take a look at this article: The future of AI is here: Potential GPT-4 use cases and early adopter projects.
Llama 2, GPT4 and GPT3.5 — speed and efficiency benchmarks
A bigger model size isn’t always an advantage. Sometimes, it’s precisely the opposite — and that’s the case here. As Llama 2 is much smaller than OpenAI models, it’s also faster than GPT-4 and -3.5 and most efficient. So if high speed and efficiency are critical for your project, Llama 2 may be your go-to option.

When is Llama 2 better than GPT-3.5 and GPT-4, and when is it not?
Let’s talk through three simple use cases to give you an even better perspective on which of these three models would be the best choice and when.
Use case no 1: building a generative AI chatbot
When to choose Llama 2?
To build a chatbot for a small business. Considering the tool’s job would be to process a relatively small number of requests with moderate complexity, Llama 2 would be a great choice here. Also, as it is an open-source model, small businesses can save money on building and maintaining a chatbot.
When to choose GPT-3.5?
To build a chatbot for a large enterprise. As GPT-3.5 is more powerful than Llama 2, it can handle more complex conversations and generate more sophisticated answers. It’s a good choice when the project requires a certain balance between the model’s performance and price.
When to choose GPT-4?
To build a chatbot for a mission-critical application. As the most powerful model out there, GPT-4 is a “go-to” when advanced reasoning, a highly professional approach, and a certain level of creativity in the problem-solving area are required. E.g., in the customer care field, that could be a tool serving as the last automated resource before there’s no other way than passing the case to a human agent.
Use case no 2: building a tool for content creation.
When to choose Llama 2?
To build a tool generating social media content. As you already know, Llama 2’s creativity level falls behind those of GPT-3.5 and GPT-4 — that’s why it won’t be a good choice if you need a tool that can effectively support your company’s marketing efforts or other strategic activities. It will, in turn, be suitable for building a tool purposed to generate relatively simple content for low-risk purposes — e.g., non-professional entertainment social media accounts.
When to choose GPT-3.5?
To build a reliable tool for supporting experienced content writers. With its skills and level of accuracy, GPT-3.5 can be a great support for creating various types of written content.
A tool powered by a well-fine-tuned model can significantly speed up the writers’ work by generating fragments of content (or full versions requiring polishing), help them avoid blockers (e.g., how to phrase a given message), and even serve as a remedy for the lack of inspiration (e.g., by helping marketer’s come up with blog topics, titles for articles, campaign ideas, etc.).
However, it’s important to note that, except for some simple cases, GPT-3.5 cannot replace skilled writers’ work. It may not be sufficient either as a tool for a junior writer — because, without sufficient experience, they won’t be able to properly assess the quality of the generated texts or polish them well enough.
That is, of course, if we speak of creating quality content.
When to choose GPT-4?
To build a content generation tool requiring minimal human involvement. GPT-4 model is a better choice when you build a tool able to generate multi-purpose, high-quality texts that require minimal to no editing & polishing. But again, remember that achieving this requires careful fine-tuning of the model.

Llama 2 and other open-source models
As you already read a bit earlier in this article, Meta’s research paper on Llama 2 includes the analysis of a human study that evaluated the new model’s performance compared to several other language models — the already covered GPT-3.5, as well as Falcon (7B & 40B variants) and MPT (7B & 30B variants).
In the table below, you can see that the Llama 2 family outperforms Falcons and MPTs on most benchmarks. Moreover, in some cases, like GSM8K, Llama 2’s superiority gets pretty significant — 56.8% (Llama 2 70B) versus 15.2% (MPT 30B) and 19.6% (Falcon 40B).
The only benchmark on which Llama 2 falls short of its competitors (more specifically, of MPT, as there’s no data on Falcon here) is HumanEval — although only in the duel between the smallest versions of the models (7B). In this case, MPT scores 18.3% while Llama only 12.8.

Llama 2 vs. GPT-3.5 vs. GPT-4 — large language models comparison summary
Even though Llama 2 is a much smaller model than OpenAI’s flagships, the fact that its performance ranks right behind GPT-3.5 on many benchmarks makes it an impressive option that surely deserves attention.
Add to it it’s open-sourced, fast, and efficient — and you’ll become even more convinced that, at least in some instances, it is an attractive alternative to GPTs in AI development services.
And even though GPT-3.5 and GPT-4 still keep their top spots on the list of the best Gen AI models, it doesn’t mean OpenAI can sit back and relax. Considering Meta was able to build a model that presents such impressive performance but at the same time is relatively small, fast, and efficient, I’d risk an assumption it may be only a matter of time before GPTs get dethroned.





