
When we met this telecom company in August 2018, they were dealing with high churn rate, falling ARPU and problems with predicting best buys for their clients. Our first mission was to reduce churn by predicting which customers are more likely to resign from the offered services. To do that, we first needed to deeply understand the problem.
Here is the story of how we helped reduce this telecom’s churn by 20% in less than 6 months.
1. Understanding
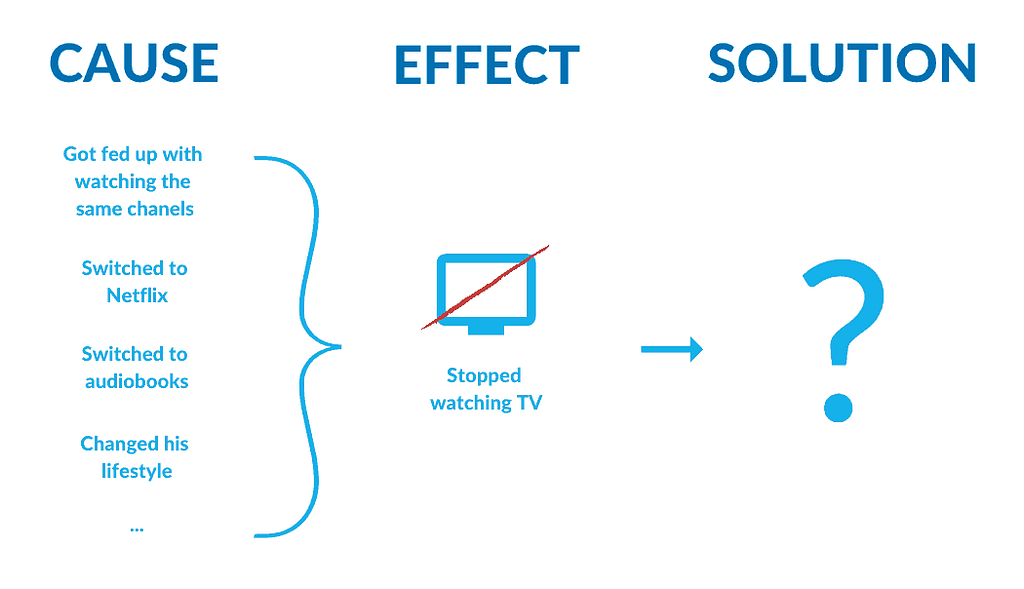
Imagine it’s Thursday afternoon. You’ve come back from work, lain down comfortably on your sofa with a bottle of beer mug of tea in your hands, and you’ve just started watching this new Netflix series… Suddenly, the phone rings.
– Hello, am I speaking to Ms. Jane Doe? I’m John Consultant from Your Telecom Provider. May I take you a while?
And just as much as you don’t want Mr. John Consultant to take any of your time, you realize that if you say “no” now, they will call again. And again.
This time, as it turns out, Mr. John Consultant wants to offer you a bigger package of TV channels.
The reason why he did that was your recent behavior. Since you bought Netflix, you’ve significantly limited the time that you spend watching TV channels. So he thought that your current package is no longer enough.
But instead of saying “Hey, if you want, you can add Netflix to your package and pay the bills all at once”, they say “We would like to offer you a great deal! You can extend your package and get 10 new channels that you will never watch”. Ok, that’s not exactly what they say. But the outcome is alike: you don’t want to extend your package. Neither with 10 extra channels nor with the fix-line phone. You may enjoy faster internet, however. So you start comparing offers from other providers.
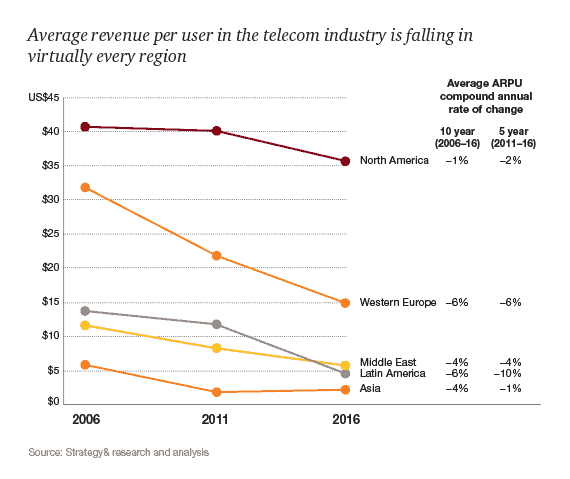
The biggest pains of telecom service providers
Customer retention
Like every other industry, telecoms struggle with their pains. Being one of the biggest industries worldwide – Insight Research projects that telecommunications services revenue worldwide will grow from $2.2 trillion in 2015 to $2.4 trillion in 2019 – telecoms struggle with customer retention and all the related issues: growing churn, unpredictable (or hard to predict) customer’s lifetime value, falling average revenue per user (ARPU).
Competition
If that wasn’t enough, the competition for telecoms in the past years has gone beyond the telecom industry. As we can read in the 2017 Telecommunications Trends report by PwC:
WhatsApp, Viber, and Apple’s iMessage already represent more than 80 percent of all messaging traffic, and Skype alone accounts for more than a third of all international voice traffic minutes. As a result, many telecom carriers are facing significant decreases in their basic communication service revenues: drop-offs of as much as 30 percent in SMS messaging, 20 percent in international voice, and 15 percent in roaming.
The real competition is not the one who sells the same product at a different price but the one who is able to approach the problem in a totally different way. This doesn’t mean, however, that telecoms will soon become extinct – nothing could be further from the truth! But they surely need to adapt.
Read also: How to increase revenue from your customers using predictive analytics
Legal restrictions
Regulations around data processing don’t make it easier. GDPR, SOPA, HIPAA, etc. exactly specify how companies can use the data of their customers, what data can they collect, and who can access it. In case of telecom companies, this regards both personal data and transmission data. To be able to process any of this information and to use it for customer profiling, the companies need to get customer permission. And as the regulations are different in different countries, the whole thing can get even more and more complicated for the international companies.
Loyalty
On top of that, the customers of this over $2.2 trillion industry are not loyal. Remember that Thursday afternoon when you received a call from John Consultant? Although Your Telecom Provider has been there with you for the past few years, although they have never let you down, you had no compunction about comparing offers from different providers, and you would have no compunction about leaving Your Telecom Provider. Have all these years meant nothing to you?
Don’t answer. For the majority of consumers, it doesn’t matter if it’s Verizon or AT&T who is their current service provider. It matters what they currently offer. So what do they offer?
Read also: Machine learning opportunities in the telecom industry
The biggest sins of telecom service providers
Low customer satisfaction
The facts are alarming. According to NPS Benchmarks:
With a Net Promoter Score® average of 24, telecom holds the lowest industry average according to the NPS® Benchmarks Report 2018. Even banking, a notoriously difficult industry for CX, has an NPS average of 37.
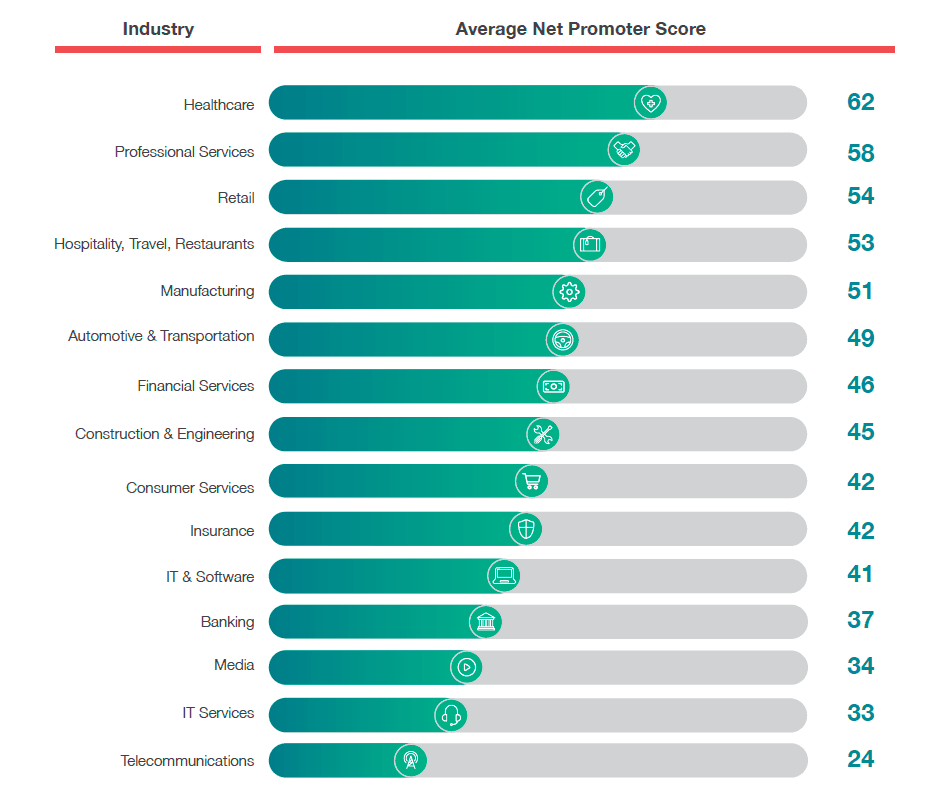
And even though acquiring new customers is neither easy, nor cheap, and it would sound reasonable to take care of the clients that they have, it appears that many telecom providers do not know their clients’ needs. And even if they do, they are not able to answer these needs – neither by adjusting their offer nor by changing the way they approach the client. The outcome of this neglect is disturbing: high churn and low ARPU.
Ineffective churn prevention strategies
Despite having huge amounts of data, service providers of the telecom industry are rarely able to use it to prevent churn. Why? First of all, they often lack the required competencies in AI development and software development in general. Then, they don’t have experience with working Agile. Their teams are not interdisciplinary, and the communication between different departments leaves a lot to be desired. So does the data itself – often collected in a chaotic, non-standardized way. Did I mention technical debt? Well, the technologies that most telecom companies use, not being adjusted to work with the new AI solutions, could be improved as well… To sum it up: we have companies that are aware of the importance of data, that collect data, but do not really know how to make use of it.
We may ask what the churn prevention strategies are. In the most common scenario… they call random clients. With databases of 1-10 million of clients, there are thousands of clients in the EoP (End of Promo). This means that the consultants need to call a lot of people who may potentially want to leave as their current plan is just about to end. The problem is that these strategies are not effective.
In this huge group of 1-10 million of clients whose service agreement is about to end, there are different types of users. Some of them will be happy to hear the offer but some will start comparing offers from different service providers. What’s more, there are users who wouldn’t care to search for different offers and would just stick to what they have. But since someone reached out… As a result, not only do the most popular churn prevention strategies not reduce the churn rate, but they often increase it.
Consultants often reach clients at the wrong time, when the clients aren’t even considering buying new services. The offers they present are not unique, they are not personalized, and they are not competitive.
But what can the telecoms actually do? Telecommunication is a huge industry. Companies operating there have millions of users. Processing the data and analyzing users’ behaviors – that are constantly changing – is extremely hard. Not only because of the amount of data, but also because it requires connecting said data in different ways. As correlation does not imply the causation, it’s easy to draw false conclusions. Just like in the analyzed case: you stopped watching TV not because you don’t have enough TV channels but because you bought Netflix. Adding more channels to your package won’t change much.
2. Development
Zero hour
Ok, so let’s sum up what we have. We have telecoms overwhelmed with the amount of data and irritated customers. The telecoms struggle with decreasing customer retention and growing churn, while customers don’t get the offers they seek.
Being a problem of most telecoms worldwide, growing churn was also a problem of one of the major Polish telecoms when they approached Neoteric. With the help of SaaS Manager, we intended to help them increase customer retention. Our major goals were to:
- implement AI and predictive analysis to better understand clients’ preferences, which was measured with the churn rate (we wanted to reduce it by 2 percentage points in one year from the product launch),
- transfer our knowledge so that the Client’s analysts would be able to build and use their own predictive models.
Solution – how we relieved some of these pains in one of the major Polish telecoms

Step 1: Prototype
After identifying the Client’s main pain points, we started the project with prototyping. The prototype we made was a sample model predicting churn. Its aim was to show that with specific data, it will be able to predict which customers want to leave, changing their service provider or resigning from the offered service for good.
The model was trained using some sample data and it was available as a service with an interface for integration. As the customers’ data processed by the model was shared through the API, it was easy to process it further – regardless of the tool that our Client’s team might want to use or will use in the future.

Step 2: More predictive models
The next step was to introduce another model and to merge it with the one predicting churn. The new model was meant to assess customers’ buying preferences. Once a customer was identified as one who was likely to leave, the model would suggest the consultant what products they should present to increase the chance of retention. The idea was to offer customers only the products that would fit their needs.
Once the two models were ready and successfully merged, it was the time to use some real data collected by the company. We initially worked with the Customer Retention Department, planning to start the pilot after 9 months from the beginning of building predictive models. Working Agile, we quickly discovered what features are really needed to start testing the models in action. After reviewing the initial plan and verifying some of the basic assumptions, we were ready to launch the pilot after less than 3 months!
That was the time when we were able to expand our activity and work with different departments. After achieving the set goals in the most demanding area of the market, we expanded our predictive models to work on the whole database and added some tools to support the Sales and Marketing Departments.
One of the most important challenges of this stage was to make sure that data records of millions of the Telecom clients are secure and no unauthorized person has access to this data – and we achieved both goals by applying proper data anonymization procedures.
As we dealt with sensitive personal data, it was very important to secure all the records from the very beginning. For us, as a third-party contractor, every end customer had to be anonymous. To ensure that, we implemented a solution that generated one-sided hashes based on customers’ data. From our perspective customer was a long identifier like “XXXX-YYYY-ZZZZ-1234” not Mr Jan Kowalski living in Warsaw, without possibility of reversing such hashing to get to know the data of the actual person. When someone from the Client’s team needed to fetch that person scores, he was able to send the request that was generating hash on the fly to get to look up a profile of desired customer – and to receive the right record back. To prevent potential data leaks, we made sure that each time someone requests the data about the specific user, his or her name was stored in the access history. If any data was exposed, it would be easy to track who was responsible for the leak.
Data anonymization was also crucial to comply with the GDPR policy. As every piece of available data was anonymous, we were able to use it to train the models. The outcome, however, was applied only to those customers, who agreed for the profiling – only those ones would receive personalized offers based on their behavior and the predictions about their future choices.
At this stage, we delivered a trained predictive model predicting the risk of churn and assessing clients’ buying preferences as well as all the mechanism that kept churn scores updated. As the model was trained on real, though anonymized, data provided by the Client, it was ready to test.

Step 3: More data
The next challenge was to make the predictions more precise and to make sure that the model is able to handle big data. At the previous stages, the predictive models were training on a part of the available data. Later, we could introduce data from various systems.
Connected to an up-to-date database and API with the scoring, the models were ready to release their full potential. The database consisted of around 150 million of records related to customers and another 75 million of additional, external metrics. Our models are able to process and update the whole database in less than 24 hours! And the scoring of the whole customers’ base lasts less than one hour. Can you imagine how long it would take a human being?
After processing the data, the predictive models could present the Sales Team the new scoring information which showed the probability of resignation along with the probability of interest in specific products. This meant that the consultant would get a report showing that Mr. John Doe is likely to change his service provider and that if he stayed, he would be interested in sport channels at 40% and in comedy channels at 60%. This way, the consultant would be able to call Mr. Doe and offer him something that may actually stop him from leaving.
As the next step, we started to work on the scoring system that would show the complex offers and organize them from the most probable to satisfy the client to the least probable. With the choice of hundreds of different (and regularly changing) offers, it would be impossible for any consultant to know all the offers, not to mention choosing the best one for each client.
Our models did not only analyze the behavior of the chosen subscriber, but also the behaviors of thousands of other subscribers – which led to creating behavior patterns. Thanks to that, the system was able to suggest offers that were personalized and adjusted to the client’s current needs.

Step 4: Pilot
That was the time for trial by fire. In order to check the performance of the designed solution and to implement further improvements, we decided to test our churn models on the full customer base. Working with the Sales Team, we aimed to decrease churn by 2 percentage points per year, but working only with the first, most difficult, most demanding segment of customers, we’ve managed to exceed this value!
The predictive models we created with SaaS Manager were able to analyze the behaviors of the clients, predict when they may want to leave and suggest the offer that can stop them. We analyzed over 200 million of records and ran the first experiments. From October 2017 to April 2018, we contributed to decreasing the number of resignations by more than twice of what was expected from us*.
The models are also able to predict when the customer may want to change their service provider and what the consultants can do to stop them. The consultant will not bother the customer before it’s needed, which creates a win-win situation: the customer is not annoyed with intrusive calls and the consultant does not waste their time on reaching customers who don’t need it.
* The exact number has to be disclosed due to NDA.

Step 5: Know-how
The final step was to transfer our know-how. As we’ve already delivered tools to do it, it was important to teach the Client’s team about creating such models so they could later train the created models or build similar ones by themselves.
We provided the Client with:
- a guide to creating predictive models,
- tools to build and train predictive models,
- Integrated Client Profile – an up-to-date database of the Client’s customers with their scoring
- trained models that predict buying preferences of our Client’s customers and the risk of their churn,
- Scoring Pipeline – set of tools to continuously update profile data and scores, including new models built by our customer analysts
With this knowledge and the toolset, the Client’s team was able to use the data provided by the predictive models we’ve build and to build and train new models. So far, the Telecom team was able to develop sales predictive models for the new offers and merge them with the ones created by our team. Another model they have built helps them predict possible breakdowns of the infrastructure and to plan the expenses related to its maintenance.
During the pilot, we were able to teach them good practices related to project management: Agile, DevOps, using clear KPIs, closely aligning with the Client’s team, and handling regular meetings – helping the Client’s team work more effectively.
Read also: Artificial Intelligence implementation in 5 steps
3. Results
After the first phase of the project, the consultants working with our predictive solutions were able to keep 5% more customers who applied to resign. After another year, we could show that when the consultants use the data provided by the models, they are able to retain more customers than when contacting customers randomly. It meant that the models are working well and that our Client’s team is able to successfully use them. Thanks to the predictive models which were generating scoring information about each customer, the consultants from the Customer Retention Department, Sales Department and Marketing Department are now able to offer customers products that fit their needs and their preferences. In less than 6 months, with the huge effort of the Client’s team, churn dropped by 20%!
Is this the holy grail for the telecoms? Perhaps. What’s important, though, is that the telecoms are not the only companies that can benefit from a similar solution. In fact, it can be applied to any company that deals with high churn rate and problems with predicting best buys for their clients: banks, retail companies, media, gaming, and gambling. With the amounts of data they collect, it is possible to train predictive models that will predict which of the customers may want to leave or what products they may be interested in. With better-fitted offers, the companies are able to reduce churn and increase the average revenue per user.
Is it difficult to do it? Yes and no. If you don’t have experience with building predictive models and dealing with big data, there are a lot of traps waiting for you. Adding more channels to your package won’t change much if you stopped watching it after you bought Netflix, remember? On the other hand, if you’re working with an experienced team offering artificial intelligence development services, the implementation of a similar AI-based solution, from analyzing the data to building and training predictive models, can take 3-6 months (depending on the available data, its amount and its quality, and on the size of the technical debt).
