First things first: JavaScript code being asynchronous does not implicate it running in more than one thread. So what does asynchronous mean exactly? Imagine making an Ajax request to fetch some data from the server. You won’t get a response immediately – you need to wait a little bit for the server to respond. What happens then is that other parts of your code are running while waiting for the response. If it weren’t for that, the interface would freeze, waiting with interpreting the rest of your code to the moment you get the response back – we don’t want that, do we?
Event Loop
An important concept in this context is an Event Loop. It goes on and on, each iteration of it being called a “tick”. If during such a tick events wait in a queue, they are going to be executed one by one. A good example is the popular setTimeout function. Its first argument is a callback – a function that is executed after a certain amount of time. When the setTimeout function is being interpreted, it is pushed to the top of the call stack. It sets up a timer, and when it goes off, it throws your callback to the end of the event loop – that means it is not going to be executed precisely after the amount of time specified – other actions waiting in the queue need to be dealt with first. When the time comes, your callback is pushed to the call stack to be executed. Same goes for your request sent to the server – when you receive a response, a function that you want to execute afterwards is thrown to the end of the queue.
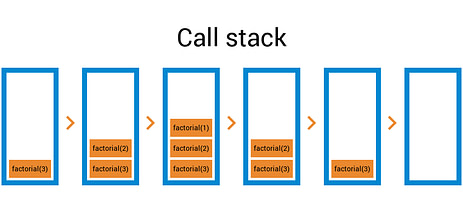
Call Stack
Call stack is a data structure under the hood – it records where we are in the program. Stepping into a function, we put it on top, returning from it would mean popping it off the stack. Let’s demonstrate a bit with some recursion:
Webworkers
As you can see, asynchronous code can be the answer to what happens between now and later, but does not mean doing a few things at a time. But what if we have some processor intensive tasks and we fear that it could freeze our UI?
The answer could be webworkers. They allow scripts to run in the background in a separate thread. It allows the main thread to run freely, not being blocked. Webworkers work in another global context, different from window. They come with some limitations: for example, you can’t directly manipulate the DOM from within the worker. The most basic (and with the best browser compatibility) type of webworker is Dedicated Worker.
To create one, you need to pass a name of the file that contains the script to a Worker constructor.
Let’s say we want to get factorials of a whole array of numbers.
To post data to it, you need to call a postMessage method.
You can communicate with it through events. If you want to listen to its response, attach an event listener to it.
This will log a factorial of a number passed to the script.
The only thing that still needs to be done is creating a factorial.worker.js file.
It needs to return the number that we are currently calculating a factorial for, and the actual result of the calculation itself.
Inside of the worker, we have a self property. It returns a reference to the WorkerGlobalScope. We can use it to communicate with the script that posted a message for the worker.
So what exactly happens here is that we create a new Worker and we listen to it sending us messages. Then, we send data to it – the worker grabs it and after doing some calculations on its own, it sends us a response. All the calculations are done in a separate thread. Pretty cool, huh?
You can run into some problems though. The first one would be that Chrome won’t use webworkers from a local file. You can use http-server for example (https://www.npmjs.com/package/http-server).
Webpack
Another problem could appear when you use webpack. It would give you an error stating 404 Not Found because it won’t know about the file that you want to load as a webworker. You need an additional loader to load files like that. Let me walk you through the process. First, install the loader using npm:
npm install –save-dev worker-loader
Then you need to add a new rule to your webpack.config.js file.
Now, if you ever happen to import a file that ends with .worker.js, the webpack will use worker-loader on it. It would make us change the code a bit. Let me use some features of ES6 with it:
To sum it up, webworkers can be of great help when trying to develop a rich application with a lot of stuff happening in the background – especially some intense calculations. Give it a try and see for yourself. I encourage you to experiment.