
Artificial intelligence is finding its way into more industries and a growing number of companies already experience the benefits of implementing AI. Even though AI is developing and gaining more popularity, many businesses still can’t find their way with this “new” technology. Why? There’s a number of reasons why a company may fear AI implementation. In 2019, O’Reilly published an ebook summarizing the findings of their surveys concerning AI adoption in enterprises and listed some of the most common factors that hold back further AI implementation. 23% of respondents say that the main reason they haven’t further adopted AI is the fact that their company culture doesn’t recognize the needs for AI. Other reasons include lack of data and lack of skilled people, and difficulties identifying appropriate business cases, among others.
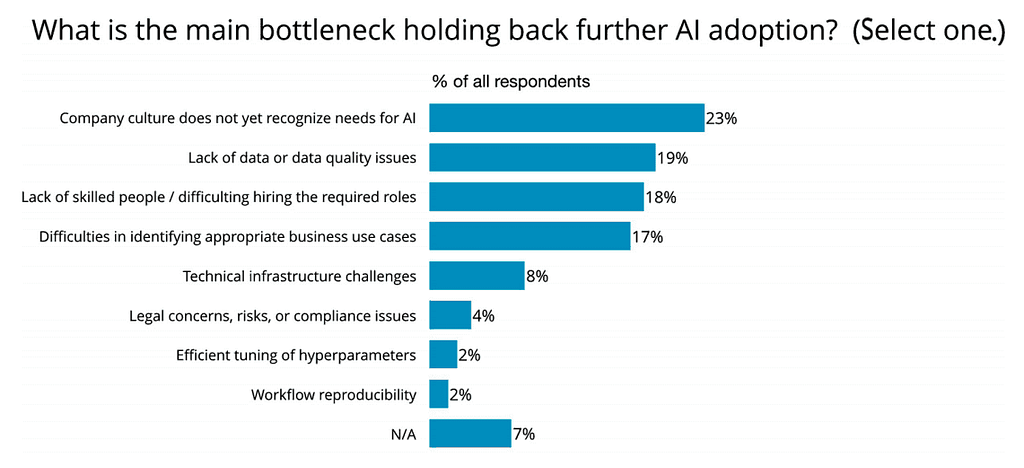
What challenges do companies face when implementing AI?
As you can see above, some of the common problems mostly include those related to people, data or business alignment. While every company is different and will experience the process of AI adoption in a different way as well, there are certain hurdles you should be aware of. In this article, I’ll guide you through some of the most common challenges and pitfalls to avoid in the implementation of AI in business and try to suggest how to be prepared to deal with them.
- Data
- Data quality and quantity
- Data labeling
- Explainability
- Case-specific learning
- Bias
- How to deal with model errors
- People
- Lack of understanding of AI among non-technical employees
- Scarcity of field specialists
- Business
- Lack of business alignment
- Difficulty assessing vendors
- Integration challenges
- Legal issues
Read also: 10 use cases of AI in manufacturing
Data – challenges of AI adoption
The data-related issues are probably the ones most companies are expecting to have. It’s a known fact that the system you build is only as good as the data that it’s given. I’ve already written about this in my previous article about the things you must consider before implementing AI in your business but since data is the key element of AI solutions, there’s a number of problems that can arise along the way.
1. Data quality and quantity
As mentioned above, the quality of the system relies heavily on the data that’s fed into it. AI systems require massive training datasets. Artificial intelligence learns from available information in a way similar to humans, but in order to identify patterns, it needs much more data than we do. It makes sense when you think about: we’re also better at tasks the more experience performing them. The difference is that AI can analyze data with a speed we as humans can’t even dream of, so it learns fast. The better data you give it, the better outcomes it will provide.
How can you solve the data problem? First of all, you need to know what data you already have and compare that to what data the model requires. In order to do that, you need to know what model you’ll be working on – otherwise, you won’t be able to specify what data is needed. List the types and categories of data you have: is the data structured or unstructured? Do you collect data about your customers’ demographics, purchase history, on-site interactions, etc? When you know what you already have, you’ll see what you’re missing.
The missing parts may be some publicly available information that the system will have easy access to, or you may have to buy data from third parties. Some types of data may are still difficult to obtain, e.g. clinical data that would allow more accurate treatment outcomes predictions. Unfortunately, at this point, you have to be prepared that not all types of data are easily available. In such cases, synthetic data comes to the rescue. Synthetic data is created artificially basing on real data or from scratch. It may be used when there isn’t enough data available to train the model. Another way to acquire data is to use open data as an addition to your data set or use Google dataset search to get data to train the model. You can also use an RPA robot to scrape publicly available data, e.g. information published on Wikipedia. When you know what data you have and what data you need, you will be able to verify what ways of expanding datasets work best for you.
2. Data labeling
A few years back, most of our data was structured or textual. Nowadays, with the Internet of Things (IoT) a large share of the data is made up of images and videos. There’s nothing wrong with that, and it may seem like there’s no problem here, but the thing is that many of the systems utilizing machine learning or deep learning are trained in a supervised way, so they require the data to be labeled. The fact that we produce vast amounts of data every day doesn’t help either; we’ve reached a point where there aren’t enough people to label all the data that’s being created. There are databases that offer labeled data, including ImageNet which is a database with over 14 million images. All of them manually annotated by ImageNet’s contributors. Even though in some cases, more appropriate data would be available elsewhere, many computer vision specialists use ImageNet anyway only because their image data is already labeled.
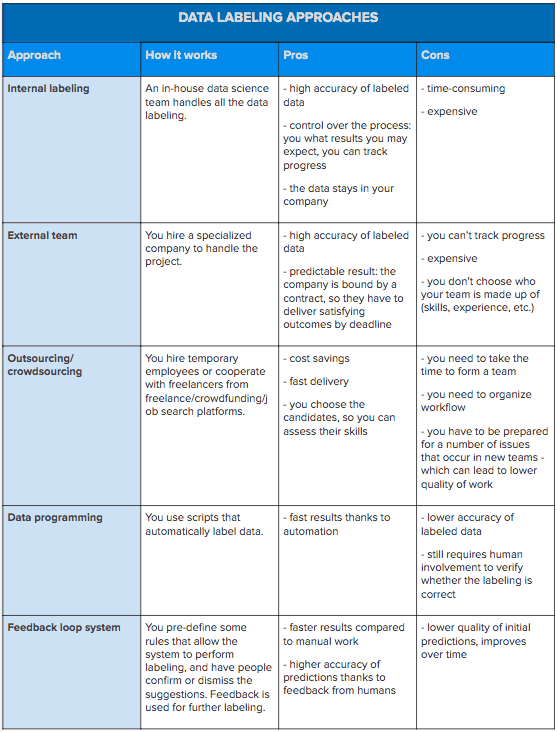
There are a few data labeling approaches that you can adopt. You can do it internally, within your company, or outsource the work, you can use synthetic labeling or data programming. All of these approaches have their pros and cons, as presented in the table below.
3. Explainability
With many “black box” models, you end up with a conclusion, e.g. a prediction, but no explanation to it. If the conclusion provided by the system overlaps with what you already know and think is right, you’re not going to question it. But what happens if you disagree? You want to know HOW the decision has been made. In many cases, the decision itself is not enough. Doctors cannot rely solely on a suggestion provided by the system when it’s about their patients’ health.

Approaches such as LIME (local interpretable model-agnostic explanations) aim to increase the transparency of models. So if AI decides that a patient has the flu, it will also show which pieces of data led to this decision: sneezing and headaches, but not the patient’s age or weight, for example. When we’re given the rationale behind the decision, it’s easier for us to assess to what extent we can trust the model.
4. Case-specific learning
Our intelligence allows us to use the experience from one field to a different one. That’s called the transfer of learning – humans can transfer learning in one context to another, similar context. Artificial intelligence continues to have difficulties carrying its experiences from one set of circumstances to another. On one hand, that’s no surprise – we know that AI is specialized – it’s meant to carry out a strictly specified task. It’s designed to answer one question only, and why would we expect it to answer a different question as well? On the other hand, the “experience” AI acquires with one task can be valuable to another, related task. Is it possible to use this experience instead of developing a new model from scratch? Transfer learning is an approach that makes it possible – the AI model is trained to carry out a certain task and then applies that learning to a similar (but distinct) activity. This means that a model developed for task A is later used as a starting point for a model for task B.
Read also: RPA and AI – What is the Difference and How Can They Work Together?
5. Bias
Bias is something many people worry about: stories of AI systems being “prejudiced” against women or people of color make the headlines every once in a while. But how does that happen? Surely, AI cannot have bad intentions. Or can it…?
No, it cannot. An assumption like that would also mean that AI is conscious and can make its own choices when in reality AI makes decisions based on the available data only. It doesn’t have opinions, but it learns from the opinions of others. And that’s where bias happens.
Bias can occur as a result of a number of factors, starting with the way of collecting data. If the data is collected by means of a survey published in a magazine, we have to be aware of the fact that the answers (data) come only from those reading said magazine, which is a limited social group. In such a case, we can’t say that the dataset is representative of the entire population.
The way data is probed is another way to develop bias: when a group of people is using some system, they may have favorite features and simply not use (or rarely use) other features. In this case, AI cannot learn about the functions that are not used with the same frequency.
But there is another thing we have to consider in terms of bias: data comes from people. People lie. People spread stereotypes. This happened in Amazon (!) recruitment when their AI recruiter turned out to be gender-biased. Since men dominated the workforce in technical departments, the system learned that male applicants are favorable and penalized the resumes that included the word “women’s”. It also downgraded graduates of all women’s colleges. You can read more about this case in my article about AI fails.
6. How to deal with model errors
Artificial intelligence is not error-free – and it is quite a challenge in AI adoption process. Human prejudices (or lies) seep into its algorithms and sometimes the results are biased. As mentioned above, there is a variety of reasons why datasets are biased. Any issues like that can cause AI to produce inaccurate outcomes, e.g. predictions.
“Bad reasoning” is another common cause of AI’s mistakes. As AI systems get more and more advanced, it can also get increasingly difficult to understand the processes in the network. So when an AI system makes a mistake, it may be difficult to identify the exact place where something went wrong. And what if the decision is about an autonomous car making a sharp turn or running someone over? Luckily, scientists developed Whitebox Testing for Deep Learning Systems. It tests the neural network with a large number of inputs and tells where its responses are wrong so they can be corrected.
But are the mistakes made by AI always so dangerous? Not always, certainly. That all depends on the use of the system. If AI is used for cybersecurity, military use, driving vehicles – more is at stake. If the system chooses a man over a woman that is as skilled, it’s an ethical issue. But sometimes the mistakes are just silly – as shows the 2015 Wired article where they describe AI that was shown an image of black and yellow stripes. And it decided it’s a school bus. It was 99% sure it was right. Only it really wasn’t right at all.
To make sure that the errors produced by AI are not critical, we must ensure high quality of input and appropriate testing.
Read also: AI in software development
People
7. Lack of understanding of AI among non-technical employees
AI implementation requires the management to have a deeper understanding of current AI technologies, their possibilities and limitations. Unfortunately, we’re surrounded by a plethora of myths concerning artificial intelligence, ranging from mundane things like the need of hiring an in-house data science team (who, you should know, only work for Facebook, Amazon, and Google, so how do you even compete) to sci-fi fantasies about smart robots ending humanity. The lack of AI know-how hinders AI adoption in many fields. Another common mistake that is caused by the lack of understanding is working towards impossible goals.
How to solve this problem? Start with education. I know, it may sound discouraging but I don’t mean you have to become a data scientist. Just have a look around your industry, watch some big players, see what use cases they’ve deployed. Learn about the current possibilities of artificial intelligence, you can do it yourself or ask an expert in the field to help you out. Once you have some knowledge, it’ll be easier for you to manage your expectations because you’ll know what AI can and cannot yet do for your business.
8. Scarcity of field specialists
In order to develop a successful AI solution, you need both the technical knowledge and business understanding. Unfortunately, it’s often one or the other. CEOs and managers lack the technical know-how necessary for AI adoption, while many data scientists aren’t very interested in how the models they develop will be used in real life. The number of AI experts that will know how to apply the tech to a given business problem is very limited. So is the number of good data scientists in general.
Companies outside the FAMGA group (Facebook, Apple, Microsoft, Google, Amazon) are struggling to attract top talent. And even if they’re attempting to build an in-house team, they aren’t sure whether they’re getting the right people. You can’t really know whether they deliver top-quality solutions if you’re lacking the technical knowledge. Small and medium enterprises may fall short on the idea of AI adoption because of their limited budget. However, outsourcing a data team is now an option as well.
Read also: AI in education
Business
9. Lack of business alignment
As shown in the chart from O’Reilly at the beginning of this article, company culture not recognizing needs for AI and difficulties in identifying business use cases are among the top barriers to AI implementation. Identifying AI business cases requires the managers to have a deep understanding of AI technologies, their possibilities and limitations. The lack of AI know-how may hinder adoption in many organizations.
But there’s another problem here. Some companies jump on the AI bandwagon with too much optimism and no clear strategy. AI implementation requires a strategic approach, setting objectives, identifying KPIs, and tracking ROI. Otherwise, you won’t be able to assess the results brought by AI and compare them with your assumptions to measure the success (or failure) of this investment.
Read also: IT business partnership
10. Difficulty assessing vendors
Just as in the case of hiring data scientists, when you’re lacking the technical know-how, you can be easily fooled. AI for business is an emerging field and it’s especially vulnerable as a large number of companies exaggerate their experience and in reality, they may not know how to use AI to solve actual business problems. One idea here is to use websites such as Clutch to identify leaders in AI development. It’s also good to see what the companies you’re considering have in their portfolio. Another approach would be to make a small step first, such as a workshop with the vendor that you see as promising. This way, you’ll see whether they understand your business, have the right skills, and know-how to address your pains.
11. Integration challenges
Integrating AI into your existing systems is a process that is more complicated than adding a plugin to your browser. The interface and elements to address your business needs have to be set up. Some rules are hard-coded. We need to consider data infrastructure needs, data storage, labeling, feeding the data into the system. Then, there’s model training and testing the effectiveness of the developed AI, creating a feedback loop to continuously improve models based on people’s actions, and data sampling to reduce the amount of data stored and run models more quickly while still producing accurate outcomes. How do you know that it’s working? How do you know that it’s worth your money?
In order to overcome possible integration challenges, you will have to join efforts with your vendor to make sure that everyone has a clear understanding of the process. It will also require the vendor to have broader expertise, not limited to building models. When AI implementation is done in a strategic manner and carried out step by step, the risk of failure is mitigated. And after you’ve successfully integrated AI into your system, you still have to train people to use the model. How do they receive outcomes produced by the model? How do they interpret the results? Your vendor should advise you on everyday use of your model and suggest how to further develop AI if it’s applicable.
12. Legal issues
I have already described some of the legal issues connected to AI in my previous article about the things to consider before implementing AI in your company. The legal system fails to keep up with the progress of technology, and questions arise. What if AI causes damage? If, by the fault of AI, something is damaged or somebody is hurt, who will take responsibility for that? The ordering party, the company who developed the AI? There are currently no rules that clearly state what has to be done in such cases. An additional issue is GDPR. With GDPR, data has become a commodity that has to be handled with care, which may be a challenge in terms of data collection: What data can be collected and in what ways? How to handle big data in a GDPR-compliant way?
There’s also the issue of sensitive data that is not obviously sensitive. And while it may not pose legal issues, it’s still a problem that could hurt your company. In general, any information whose leakage threatens the position of your company, or its image, should be considered sensitive. Imagine a situation when the data about your employees’ trainings and courses leaks out of your system. That doesn’t seem threatening, does it? But if there are some unusual positions on the list, let’s say there was training on dealing with workplace bullying, such information can be misinterpreted and spread to damage your business.
Read also: Starting with AI
How to deal with the challenges of AI adoption?
You have to remember that you can’t handle all the issues yourself. The first thing to do is to familiarize yourself with AI – this way it will be easier for you to understand the process. Then, when you create an AI strategy, you will have to recognize the issues to look out to. With a strategic and step by step approach, you will be able to go through the process of AI implementation more smoothly. Is a bug-free implementation possible? Nothing is ever 100% perfect, but being prepared for any problems that can occur along the way is already a huge benefit.
