

Learn from the best: Netflix, Amazon, and Google
The biggest players use recommendation engines to boost sales, increase revenue, and improve customer experience. They have experimented with recommenders and worked out the best ways to use, so now businesses all around the world can learn from them and follow their lead. Though you may not necessarily be the next Netflix, a recommender system can be perfectly suited to your business needs – and it should, as using any AI technology should be done strategically, and not in an attempt to blindly follow a market leader.
In this article, we’ll describe how Netflix, Amazon, and Google use recommendations and guide you through the steps to follow while setting up your recommendation engine.
If you’re interested in types of recommender systems: what possibilities and limitations are characteristic of collaborative filtering, content-based filtering, and hybrid recommendation systems, and how using a recommender system benefits companies, read the article How to boost sales with a recommender system.
And now, let’s have a look at how other companies use recommendation engines.
Netflix recommender system

Source: HBS
Many services aspire to create a recommendation engine as good as that of Netflix. The details of how it works under the hood are Netflix’s secret, but they do share some information on the elements that the system takes into account before it generates recommendations.
On their website, they list what data they collect for the recommendations:
Whenever you access the Netflix service, our recommendations system strives to help you find a show or movie to enjoy with minimal effort. We estimate the likelihood that you will watch a particular title in our catalog based on a number of factors including:
- your interactions with our service (such as your viewing history and how you rated other titles),
- other members with similar tastes and preferences on our service, and
- information about the titles, such as their genre, categories, actors, release year, etc.
In addition to knowing what you have watched on Netflix, to best personalize the recommendations we also look at things like:
- the time of day you watch,
- the devices you are watching Netflix on, and
- how long you watch.
All of these pieces of data are used as inputs that we process in our algorithms. (An algorithm is a process or set of rules followed in a problem-solving operation.) The recommendations system does not include demographic information (such as age or gender) as part of the decision making process.
In an interview with Wired, Todd Yellin, Netflix’s vice president of product innovation, compares the system to a three-legged stool:
The three legs of this stool would be Netflix members; taggers who understand everything about the content; and our machine learning algorithms that take all of the data and put things together.
So the first leg of the stool is the users: what they watch, when they watch it. Netflix splits the users up into more than two thousand taste groups. The system looks for similarities between users (collaborative filtering) to group them.
The second leg is the content. Information about the content is gathered from dozens of in-house and freelance staff who watch every show on Netflix to tag it. There is a wide variety of tags to differentiate the types of content referring to the genre, setting, characters, etc.
And the last leg is machine learning. The system is fed with data about content and user behavior, and sophisticated machine learning algorithms figure out what should be weighed – what’s the most important.
Amazon recommender system

Amazon’s recommendation system is yet another success story, one of the many ways the company uses AI to kill competitors. We wish we could put it more mildly, but let’s be honest: competing with Amazon is virtually impossible (at least now). It started off taking traffic away from other online stores but expanded to brick-and-mortar, and with the great reputation they have, they’ve grown to be the first choice for product searches for an increasing number of people. And let’s not forget that Alexa can do your shopping. So whatever it is that Amazon does, it’s worth to have a look at. While many of their ideas sound crazy (flying warehouse, anyone?), their focus on data-driven marketing has proven successful and is a great lesson for any company.
Our mission is to delight our customers by allowing them to serendipitously discover great products.
– Said an Amazon spokesperson in an interview with Fortune.
Amazon mastered recommendations: they’re displayed while browsing through products, an in so many places: you’ve got “Customers who bought this item also bought”, “What other item do customers buy after viewing this item?”, “Customers who viewed this item also viewed, and “Inspired by your browsing history”, “More items to explore”, “Related to items you viewed”… And that’s just on the product page. You’ve also got recommended items on the main page – a list of the most popular items per category and a set of personalized suggestions. Then, you click “Add to cart” and more recommendations are shown. Related products, new releases, bestsellers, related sponsored products. Amazon also includes recommendations in emails they send to customers. These suggestions, too, are based on each customer’s individual browsing and purchase behavior.
Is Amazon’s system perfect? No, nothing ever is, and there’s still room for improvement. Most of us have at least once received a totally irrelevant recommendation. Haven’t you? But the way they do it is impressive – even though recommendations are displayed in so many places that it can be overwhelming, it works. People click through related items, discover new products, add them to wishlists, and buy more. They may even buy products that they wouldn’t buy separately – say Earl Grey tea – because they’re already shopping, it’s suggested, and it doesn’t add any shipping costs. Items per order go up, sales go up, customer satisfaction goes up. Isn’t it a win for all?
Though Amazon has never commented on the numbers showing how much the recommendations influence their revenue, it has been reported that they saw a 29% increase in sales after they’ve introduced recommendations. We won’t know what the real number is, but we all are shoppers too: and have you never been tempted by the “You might also like” list?
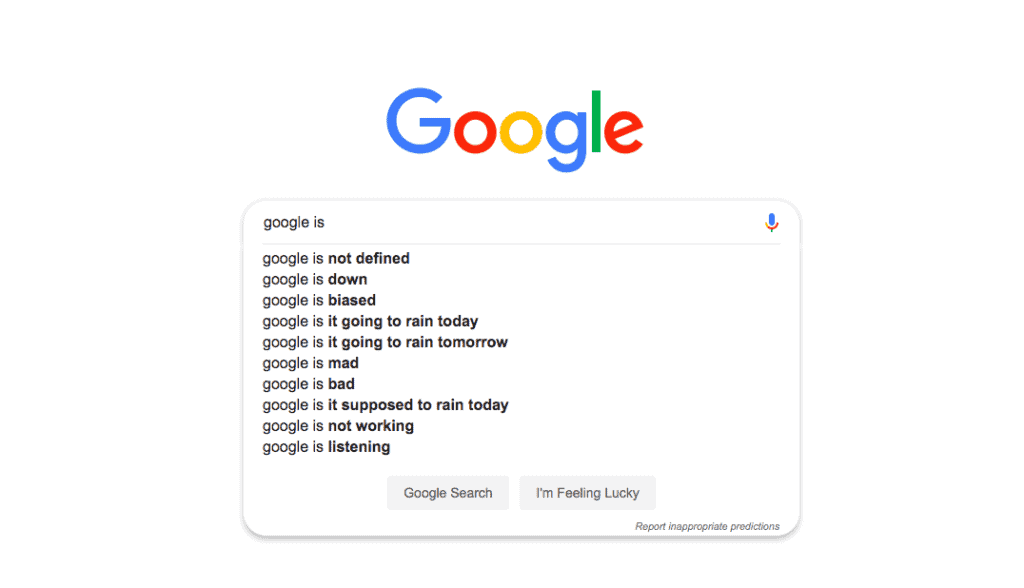
Did you realize that Google is a recommendation engine, too?
The second you start typing in the search box, Google’s suggestions appear. But they’re not the same for everyone in the world. Google uses machine learning, predictive analytics, natural language processing to suggest relevant phrases through autocomplete. What do they take into consideration? Query volume, geography, and keyword popularity definitely play a role, but there’s also the part of your own search history. You can see that when looking for the same phrase again, and the thing you’ve Googled before is at the top of the list. Google also fixes our spelling mistakes and finds relevant results anyway.
And what about Google ads? They’re targeted – recommended to specific users who will be interested in given items. In order to maximize the ads revenue, Google uses recommender systems. Google knows what you do, where you live, where you work. It knows what you like – because that’s what you look for. It probably also knows about many of your problems or worries – don’t you google stuff first before you share a problem with anyone, even a doctor? Many people do. Having all this information about every user, Google can accurately assess how much they will like a given product to serve them with targeted ads.
How to build a recommender system – steps to follow
Before you move on to the actual development of a recommender system, there are some things you need to have figured out. Building a recommender system requires a strategic approach, just like any data science project for that matter. Here are some steps to follow while building recommender systems:
Step 1: Outline a recommendation strategy
You can’t expect anything to go right if you approach it without a strategy. Ask yourself some questions:
How often do you need to serve the recommended content?
Real-time recommendations that take into account the most recent data are nice but more difficult to maintain. On the other hand, batch processing is easier to maintain (and in many cases perfectly sufficient) but does not reflect the recent changes in data.
How will you handle the cold start problem?
When a new customer starts using your platform, what will you recommend to them? The most common approach here is to serve them the most popular and the most recent content. That’s a good place to start learning what the user is interested in. However, you can also start with a clever onboarding process that will collect some basic information about what the user is interested in. That’s the case with Netflix, where the first step is to choose some movies and series that you’ve already seen and enjoyed. In the case of e-commerce businesses, you can simply recommend items similar to those they have already displayed.
Do you want more feed diversity?
Recommender systems filter the content and may sometimes filter it too strictly. If a user interacted with one type of content for some time – let’s say they watched 3 thrillers in a row, flooding their feed with thrillers is some idea, but is it a good idea? You can add some layer of randomization, suggesting other items as well to introduce more diversity.
Do you want to explain the recommendations?
Some suggestions are marked as “Because you watched X” or “Because you follow Y”, or they’re accompanied by the accuracy rate – on Netflix, next to each recommendation, there’s a certain percentage. It’s great to be able to show how your system came up with the recommendation, but it’s not that simple. Many machine learning models are black boxes: after they’re trained, they generate recommendations but without giving the rationale behind the decisions. The explanation is often not necessary, but if the recommendations are not accurate, users may question the model’s decisions. There are approaches addressing this issue, but the simplest solution is to state a few rules that are used in generating recommendations. These rules should be understandable to users but not too general like “based on historical data”. Tell your users how you do it, in simple steps, like: we collect the information about your activity and preferences and compare it to the activity of other users to find similarities; we then use this information to recommend items that users with similar preferences enjoyed. Make sure you are clear about whether you process any personal information.
Step 2: Collect and organize relevant data
You cannot have a recommendation engine without data. Whatever type of a recommender system you choose, data is a must. As you collect information, make sure it is organized in some standard form. Having all information in the same form makes it easier to compare user A to other users, or item A to other items. The more relevant data you collect, the better predictions you get. That’s why some services have very specific sub-categories of products, like Netflix’s sub-genres.
Step 3: Identify similarities
Between users, between products, or both. Compare the users or items to identify patterns. This can be done with the use of clustering algorithms, for example, the k-nearest neighbor (KNN) algorithm that recommends items that are closest to the ones users already liked. It’s the most intuitive machine learning algorithm – because it works similarly to how we give recommendations based on our knowledge of a person.
Step 4: Track user interactions
The content you serve to users as recommendations is what you assume they will be interested in. With sufficient data, it’s very probable they actually will enjoy the suggested items, but you can’t just sit down and relax once the recommendation engine is in place. Track user interactions to assess user engagement and the quality of predictions. If you use systems including likes, upvotes, or ratings, your customers can provide you with feedback that helps further improve the recommendation engine.
Learn, don’t copy
Observing inspiring examples from successful companies is good, copying their exact solution – not so much. Your data science project should be chosen to strengthen your business, and be feasible. Make sure you and your organization are ready for the AI project, know what you expect from the data science team and what results you want to see.





{kind=link}